class: center, middle  ### Advanced Machine Learning with scikit-learn # Text Data Andreas C. Müller Columbia University, scikit-learn .smaller[https://github.com/amueller/ml-training-advanced] ??? FIXME make all bar-plots uniform style! FIXME tfidf before n-grams FIXME explain L2 normalization and intuition. FIXME is logisticregressionCV efficient here? sag? --- # More kinds of data - So far: * Fixed number of features * Contiguous * Categorical -- - Next up: * No pre-defined features * Free text * Images * (Audio: not this class) ??? * Need to create fixed-length description --- # Typical Text Data <br> .center[  ] <br> <br> .center[  ] ??? --- # Other Types of text data .center[ 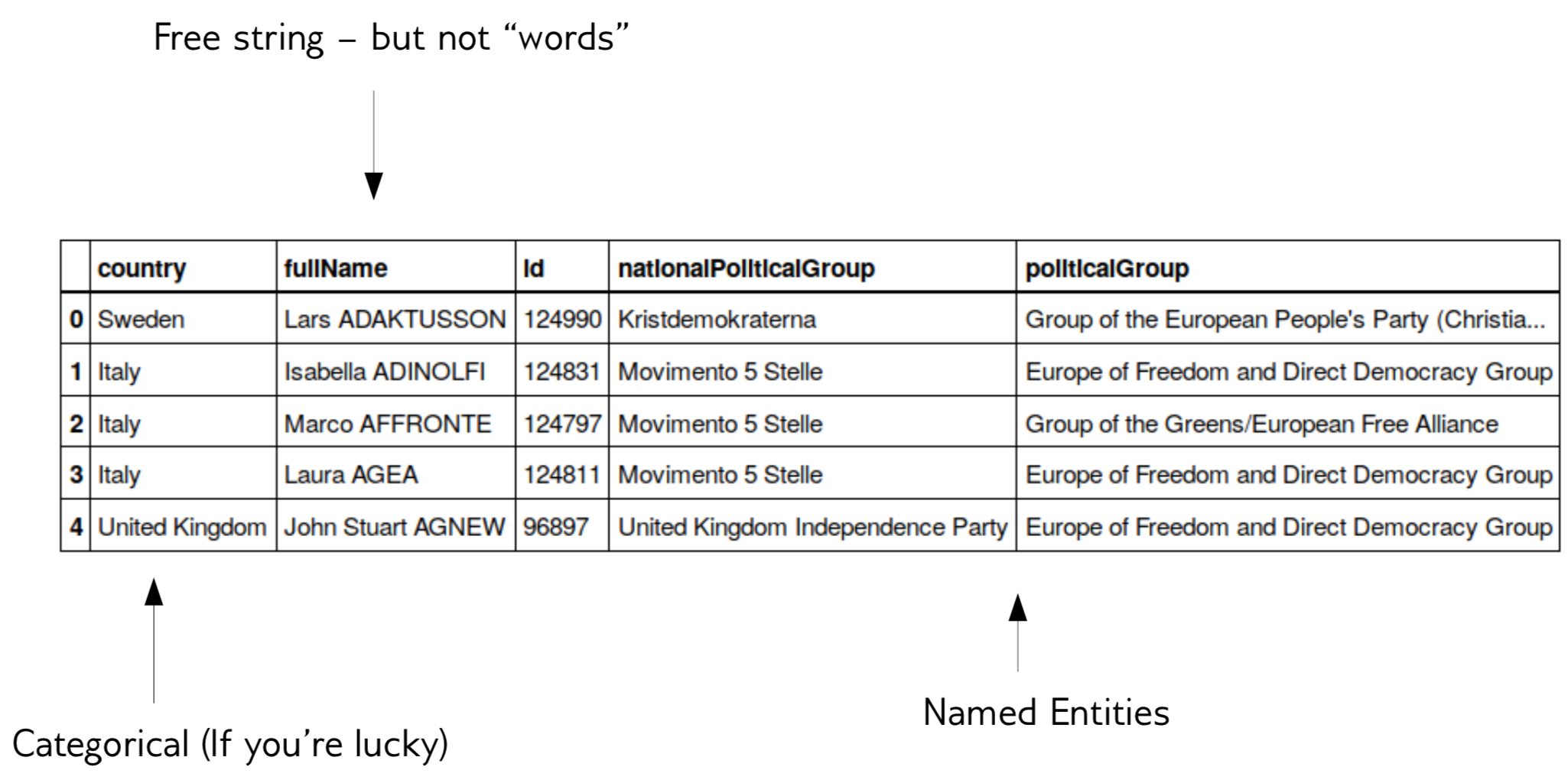 ] ??? --- # Bag of Words <br> .center[  ] ??? --- # Toy Example .smaller[ ```python malory = ["Do you want ants?", "Because that’s how you get ants."] ``` ```python from sklearn.feature_extraction.text import CountVectorizer vect = CountVectorizer() vect.fit(malory) print(vect.get_feature_names()) ``` ``` ['ants', 'because', 'do', 'get', 'how', 'that', 'want', 'you'] ``` ```python X = vect.transform(malory) print(X.toarray()) ``` ``` array([[1, 0, 1, 0, 0, 0, 1, 1], [1, 1, 0, 1, 1, 1, 0, 1]]) ``` ] ??? Consider two documents in a dataset "malory" --- class: spacious # "bag" ```python print(malory) print(vect.inverse_transform(X)[0]) print(vect.inverse_transform(X)[1]) ``` ``` ['Do you want ants?', 'Because that’s how you get ants.'] ['ants' 'do' 'want' 'you'] ['ants' 'because' 'get' 'how' 'that' 'you'] ``` ??? --- class: center, middle # Text classification example: # IMDB Movie Reviews --- # Data loading ```python from sklearn.datasets import load_files reviews_train = load_files("../data/aclImdb/train/") text_trainval, y_trainval = reviews_train.data, reviews_train.target print("type of text_train:", type(text_trainval)) print("length of text_train:", len(text_trainval)) print("class balance:", np.bincount(y_trainval)) ``` ``` type of text_trainval: <class 'list'> length of text_trainval: 25000 class balance: [12500 12500] ``` ??? --- # Data loading ```python print("text_train[1]:") print(text_trainval[1].decode()) ``` .smaller[ ``` text_train[1]: 'Words can't describe how bad this movie is. I can't explain it by writing only. You have too see it for yourself to get at grip of how horrible a movie really can be. Not that I recommend you to do that. There are so many clichés, mistakes (and all other negative things you can imagine) here that will just make you cry. To start with the technical first, there are a LOT of mistakes regarding the airplane. I won't list them here, but just mention the coloring of the plane. They didn't even manage to show an airliner in the colors of a fictional airline, but instead used a 747 painted in the original Boeing livery. Very bad. The plot is stupid and has been done many times before, only much, much better. There are so many ridiculous moments here that i lost count of it really early. Also, I was on the bad guys' side all the time in the movie, because the good guys were so stupid. "Executive Decision" should without a doubt be you're choice over this one, even the "Turbulence"-movies are better. In fact, every other movie in the world is better than this one.' ``` ] ??? all the code is in the github repo. --- # Vectorization ```python text_train_val = [doc.replace(b"<br />", b" ") for doc in text_train_val] text_train, text_val, y_train_, y_val = train_test_split( text_trainval, y_trainval, stratify=y_trainval, random_state=0) vect = CountVectorizer() X_train = vect.fit_transform(text_train) X_val = vect.transform(text_val) X_train ``` ``` <18750x66651 sparse matrix of type '<class 'numpy.int64'>' with 2580448 stored elements in Compressed Sparse Row format> ``` --- # Vocabulary ```python feature_names = vect.get_feature_names() print(feature_names[:10]) print(feature_names[20000:20020]) print(feature_names[::2000]) ``` -- .smaller[ ``` ['00', '000', '0000000000001', '00001', '00015', '000s', '001', '003830', '006', '007'] ``` ] -- .smaller[ ``` ['eschews', 'escort', 'escorted', 'escorting', 'escorts', 'escpecially', 'escreve', 'escrow', 'esculator', 'ese', 'eser', 'esha', 'eshaan', 'eshley', 'esk', 'eskimo', 'eskimos', 'esmerelda', 'esmond', 'esophagus'] ['00', 'ahoy', 'aspects', 'belting', 'bridegroom', 'cements', 'commas', 'crowds', 'detlef', 'druids', 'eschews', 'finishing', 'gathering', 'gunrunner', 'homesickness', 'inhumanities', 'kabbalism', 'leech', 'makes', 'miki', 'nas', 'organ', 'pesci', 'principally', 'rebours', 'robotnik', 'sculptural', 'skinkons', 'stardom', 'syncer', 'tools', 'unflagging', 'waaaay', 'yanks'] ``` ] --- # Classification <br> ```python from sklearn.linear_model import LogisticRegressionCV lr = LogisticRegressionCV().fit(X_train, y_train) ``` ```python lr.C_ ``` ``` array([ 0.046]) ``` ```python lr.score(X_val, y_val) ``` ``` 0.882 ``` --- class: middle .center[  ] --- class:spacious # Soo many options! - How to tokenize? - How to normalize words? - What to include in vocabulary? --- # Restricting the Vocabulary --- # Stop Words ```python vect = CountVectorizer(stop_words='english') vect.fit(malory) print(vect.get_feature_names()) ``` ``` ['ants', 'want'] ``` ```python from sklearn.feature_extraction.text import ENGLISH_STOP_WORDS print(list(ENGLISH_STOP_WORDS)) ``` .tiny-code[ ``` ['former', 'above', 'inc', 'off', 'on', 'those', 'not', 'fifteen', 'sometimes', 'too', 'is', 'move', 'much', 'own', 'until', 'wherein', 'which', 'over', 'thru', 'whoever', 'this', 'indeed', 'same', 'three', 'whatever', 'us', 'somewhere', 'after', 'eleven', 'most', 'de', 'full', 'into', 'being', 'yourselves', 'neither', 'he', 'onto', 'seems', 'who', 'between', 'few', 'couldnt', 'i', 'found', 'nobody', 'hereafter', 'therein', 'together', 'con', 'ours', 'an', 'anyone', 'became', 'mine', 'myself', 'before', 'call', 'already', 'nothing', 'top', 'further', 'thereby', 'why', 'here', 'next', 'these', 'ever', 'whereby', 'cannot', 'anyhow', 'thereupon', 'somehow', 'all', 'out', 'ltd', 'latterly', 'although', 'beforehand', 'hundred', 'else', 'per', 'if', 'afterwards', 'any', 'since', 'nor', 'thereafter', 'it', 'around', 'them', 'alone', 'up', 'sometime', 'very', 'give', 'elsewhere', 'always', 'cant', 'due', 'forty', 'still', 'either', 'was', 'beyond', 'fill', 'hereupon', 'no', 'might', 'by', 'everyone', 'five', 'often', 'several', 'and', 'something', 'formerly', 'she', 'him', 'become', 'get', 'could', 'ten', 'below', 'had', 'how', 'back', 'nevertheless', 'namely', 'herself', 'none', 'be', 'himself', 'becomes', 'hereby', 'never', 'along', 'while', 'side', 'amoungst', 'toward', 'made', 'their', 'part', 'everything', 'his', 'becoming', 'a', 'now', 'am', 'perhaps', 'moreover', 'seeming', 'themselves', 'name', 'etc', 'more', 'another', 'whither', 'see', 'herein', 'whom', 'among', 'un', 'via', 'every', 'cry', 'me', 'should', 'its', 'again', 'co', 'itself', 'two', 'yourself', 'seemed', 'under', 'then', 'meanwhile', 'anywhere', 'beside', 'seem', 'please', 'behind', 'sixty', 'were', 'in', 'upon', 'than', 'twelve', 'when', 'third', 'to', 'though', 'hence', 'done', 'other', 'where', 'someone', 'of', 'whose', 'during', 'many', 'as', 'except', 'besides', 'for', 'within', 'mostly', 'but', 'nowhere', 'we', 'our', 'through', 'both', 'bill', 'yours', 'less', 'well', 'have', 'therefore', 'one', 'last', 'throughout', 'can', 'mill', 'against', 'anyway', 'at', 'system', 'noone', 'that', 'would', 'only', 'rather', 'wherever', 'least', 'are', 'empty', 'almost', 'latter', 'front', 'my', 'amount', 'put', 'what', 'whereas', 'across', 'whereupon', 'otherwise', 'thin', 'others', 'go', 'thus', 'enough', 'her', 'fire', 'may', 'once', 'show', 'because', 'ourselves', 'some', 'such', 'yet', 'eight', 'sincere', 'from', 'been', 'twenty', 'whether', 'without', 'you', 'do', 'everywhere', 'six', 'however', 'first', 'find', 'hers', 'towards', 'will', 'also', 'even', 'or', 're', 'describe', 'serious', 'so', 'anything', 'must', 'ie', 'the', 'whenever', 'thick', 'bottom', 'they', 'keep', 'your', 'has', 'about', 'each', 'four', 'eg', 'interest', 'hasnt', 'detail', 'amongst', 'take', 'thence', 'down', 'fifty', 'whence', 'whereafter', 'nine', 'with', 'whole', 'there'] ``` ] ??? - not a very good stop-word list? Why is system in it? bill? - For supervised learning often little effect on large corpuses (on small corpuses and for unsupervised learning it can help) --- # Infrequent Words - Remove words that appear in less than 2 documents: .smaller[ ```python vect = CountVectorizer(min_df=2) vect.fit(malory) print(vect.get_feature_names()) ``` ``` ['ants', 'you'] ``` ] - Restrict vocabulary size to max_features most frequent words: .smaller[ ```python vect = CountVectorizer(max_features=4) vect.fit(malory) print(vect.get_feature_names()) ``` ``` ['ants', 'because', 'do', 'you'] ``` ] --- .smaller[ ```python vect = CountVectorizer(min_df=2) X_train_df2 = vect.fit_transform(text_train) vect = CountVectorizer(min_df=4) X_train_df4 = vect.fit_transform(text_train) X_val_df4 = vect.transform(text_val) print(X_train.shape) print(X_train_df2.shape) print(X_train_df4.shape) ``` ``` (18750, 66651) (18750, 39825) (18750, 26928) ``` ```python lr = LogisticRegressionCV().fit(X_train_df4, y_train) lr.C_ ``` ``` array([ 0.046]) ``` ```python lr.score(X_val_df4, y_val) ``` ``` 0.881 ``` ] ??? - Removed nearly 1/3 of features! - As good as before --- # N-grams: Beyond single words - Bag of words completely removes word order. - "didn't love" and "love" are very different! -- .center[ 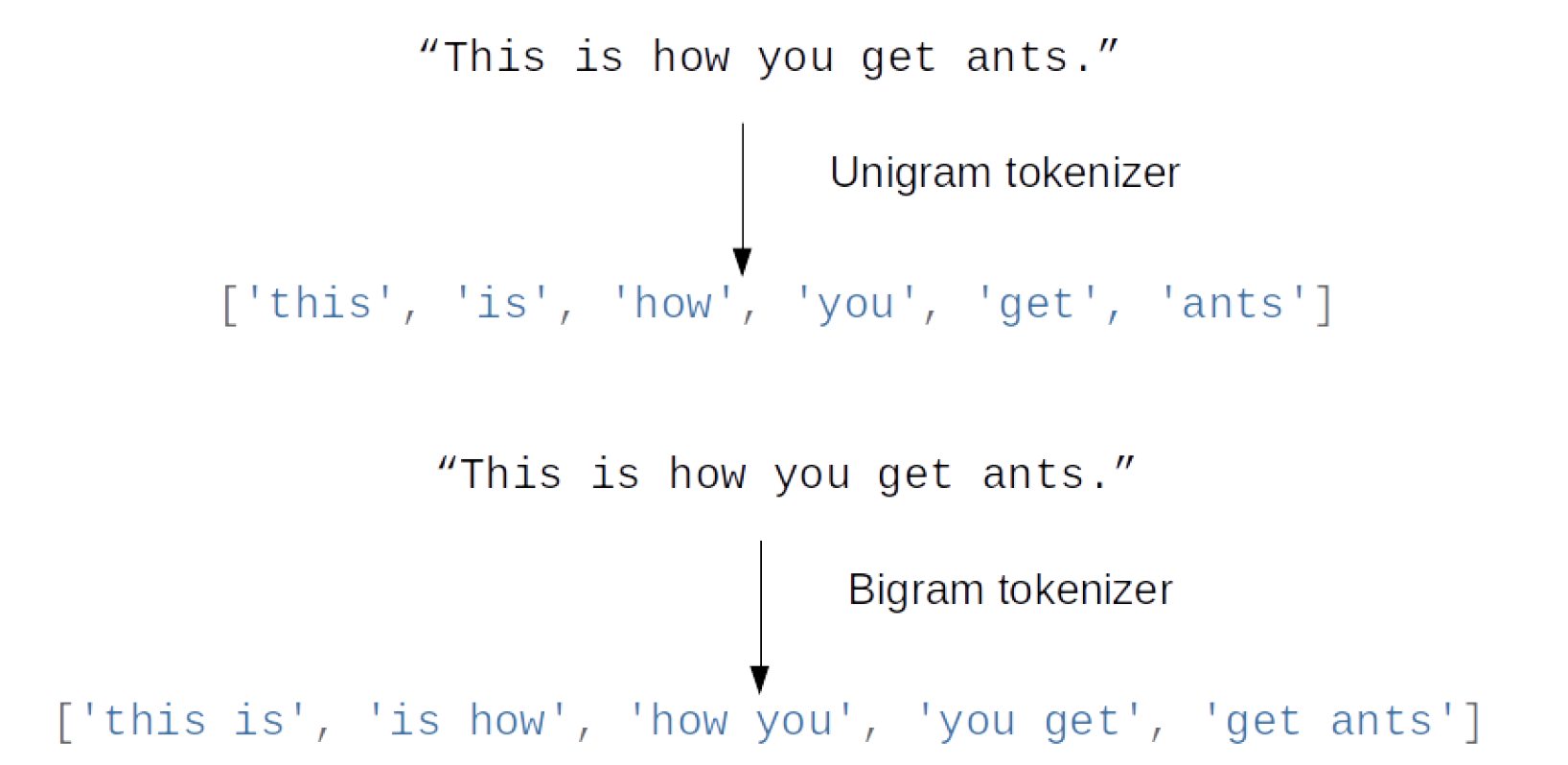 ] ??? - N-grams: tuples of consecutive words --- # Bigrams toy example .tiny-code[ ```python cv = CountVectorizer(ngram_range=(1, 1)).fit(malory) print("Vocabulary size:", len(cv.vocabulary_)) print("Vocabulary:", cv.get_feature_names()) ``` ``` Vocabulary size: 8 Vocabulary: ['ants', 'because', 'do', 'get', 'how', 'that', 'want', 'you'] ``` ```python cv = CountVectorizer(ngram_range=(2, 2)).fit(malory) print("Vocabulary size:", len(cv.vocabulary_)) print("Vocabulary:") print(cv.get_feature_names()) ``` ``` Vocabulary size: 8 Vocabulary: ['because that', 'do you', 'get ants', 'how you', 'that how', 'want ants', 'you get', 'you want'] ``` ```python cv = CountVectorizer(ngram_range=(1, 2)).fit(malory) print("Vocabulary size:", len(cv.vocabulary_)) print("Vocabulary:") print(cv.get_feature_names()) ``` ``` Vocabulary size: 16 Vocabulary: ['ants', 'because', 'because that', 'do', 'do you', 'get', 'get ants', 'how', 'how you', 'that', 'that how', 'want', 'want ants', 'you', 'you get', 'you want'] ``` ] ??? - Typically: higher n-grams lead to blow up of feature space! --- # N-grams on IMDB data ``` Vocabulary Sizes 1-gram (min_df=4): 26928 2-gram (min_df=4): 128426 1-gram & 2-gram (min_df=4): 155354 1-3gram (min_df=4): 254274 1-4gram (min_df=4): 289443 ``` ```python cv = CountVectorizer(ngram_range=(1, 4)).fit(text_train) print("Vocabulary size 1-4gram:", len(cv.vocabulary_)) ``` ``` Vocabulary size 1-4gram (min_df=1): 7815528 ``` - More than 20x more 4-grams! --- #Stop-word impact on bi-grams ```python cv = CountVectorizer(ngram_range=(1, 2), min_df=4) cv.fit(text_train) print("(1, 2), min_df=4:", len(cv.vocabulary_)) cv = CountVectorizer(ngram_range=(1, 2), min_df=4, stop_words="english") cv.fit(text_train) print("(1, 2), stopwords, min_df=4:", len(cv.vocabulary_)) ``` ``` (1, 2), min_df=4: 155354 (1, 2), stopwords, min_df=4: 81085 ``` --- # Stop-word impact on 4-grams ```python cv4 = CountVectorizer(ngram_range=(4, 4), min_df=4) cv4.fit(text_train) cv4sw = CountVectorizer(ngram_range=(4, 4), min_df=4, stop_words="english") cv4sw.fit(text_train) print(len(cv4.get_feature_names())) print(len(cv4sw.get_feature_names()))``` ``` 31585 369 ``` --- ``` ['worst movie ve seen' '40 year old virgin' 've seen long time' 'worst movies ve seen' 'don waste time money' 'mystery science theater 3000' 'worst film ve seen' 'lose friends alienate people' 'best movies ve seen' 'don waste time watching' 'jean claude van damme' 'really wanted like movie' 'best movie ve seen' 'rock roll high school' 'don think ve seen' 'let face music dance' 'don say didn warn' 'worst films ve seen' 'fred astaire ginger rogers' 'ha ha ha ha' 'la maman et la' 'maman et la putain' 'left cutting room floor' 've seen ve seen' 'just doesn make sense' 'robert blake scott wilson' 'late 70 early 80' 'crouching tiger hidden dragon' 'low budget sci fi' 'movie ve seen long' 'toronto international film festival' 'night evelyn came grave' 'good guys bad guys' 'low budget horror movies' 'waste time watching movie' 'vote seven title brazil' 'bad bad bad bad' 'morning sunday night monday' '14 year old girl' 'film based true story' 'don make em like' 'silent night deadly night' 'rating saturday night friday' 'right place right time' 'friday night friday morning' 'night friday night friday' 'friday morning sunday night' 'don waste time movie' 'saturday night friday night' 'really wanted like film'] ``` --- .center[ 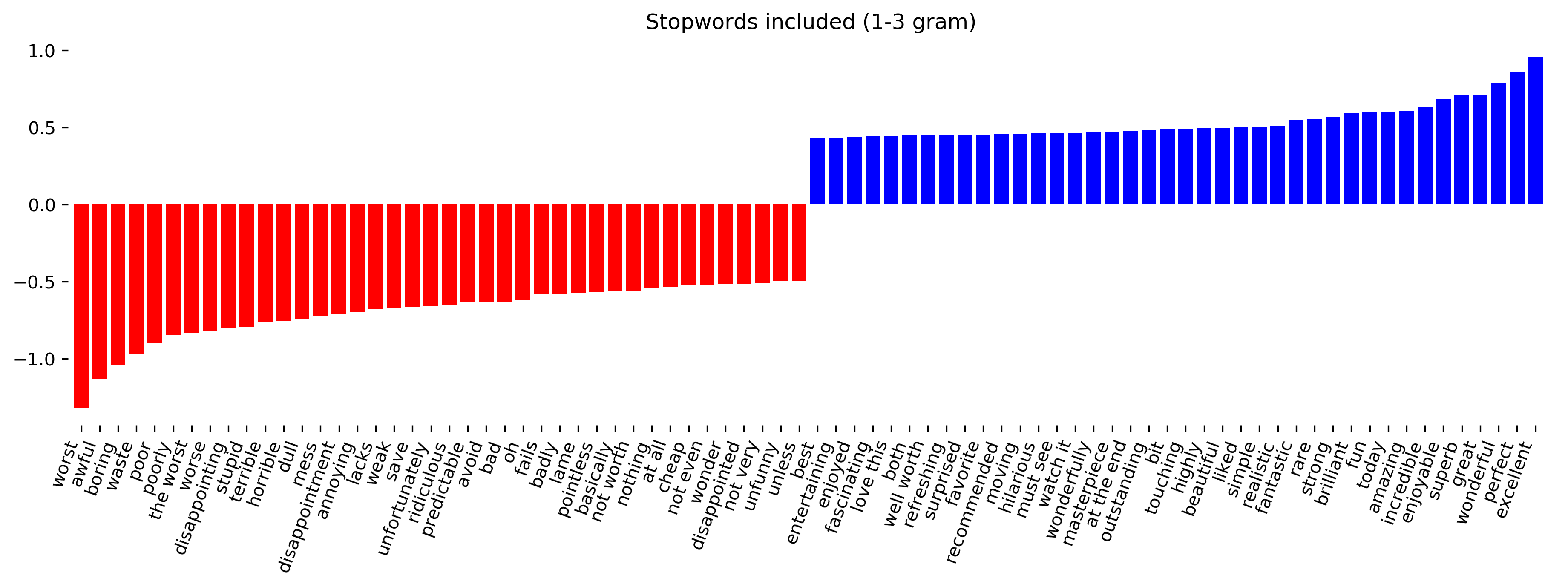 ] .center[ 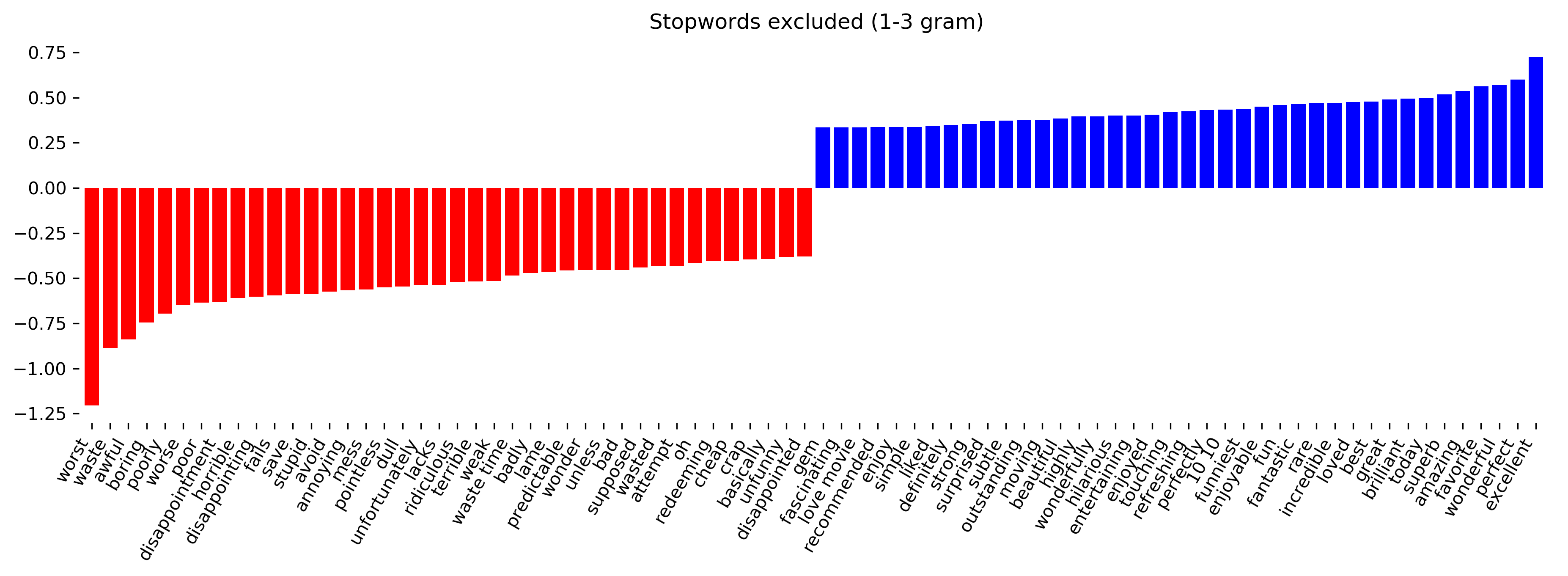 ] ??? Stopwords removed fares slightly worse --- .tiny-code[ ```python my_stopwords = set(ENGLISH_STOP_WORDS) my_stopwords.remove("well") my_stopwords.remove("not") my_stopwords.add("ve") ``` ```python vect3msw = CountVectorizer(ngram_range=(1, 3), min_df=4, stop_words=my_stopwords) X_train3msw = vect3msw.fit_transform(text_train) lr3msw = LogisticRegressionCV().fit(X_train3msw, y_train) X_val3msw = vect3msw.transform(text_val) lr3msw.score(X_val3msw, y_val) ``` ``` 0.883 ``` ] .center[ 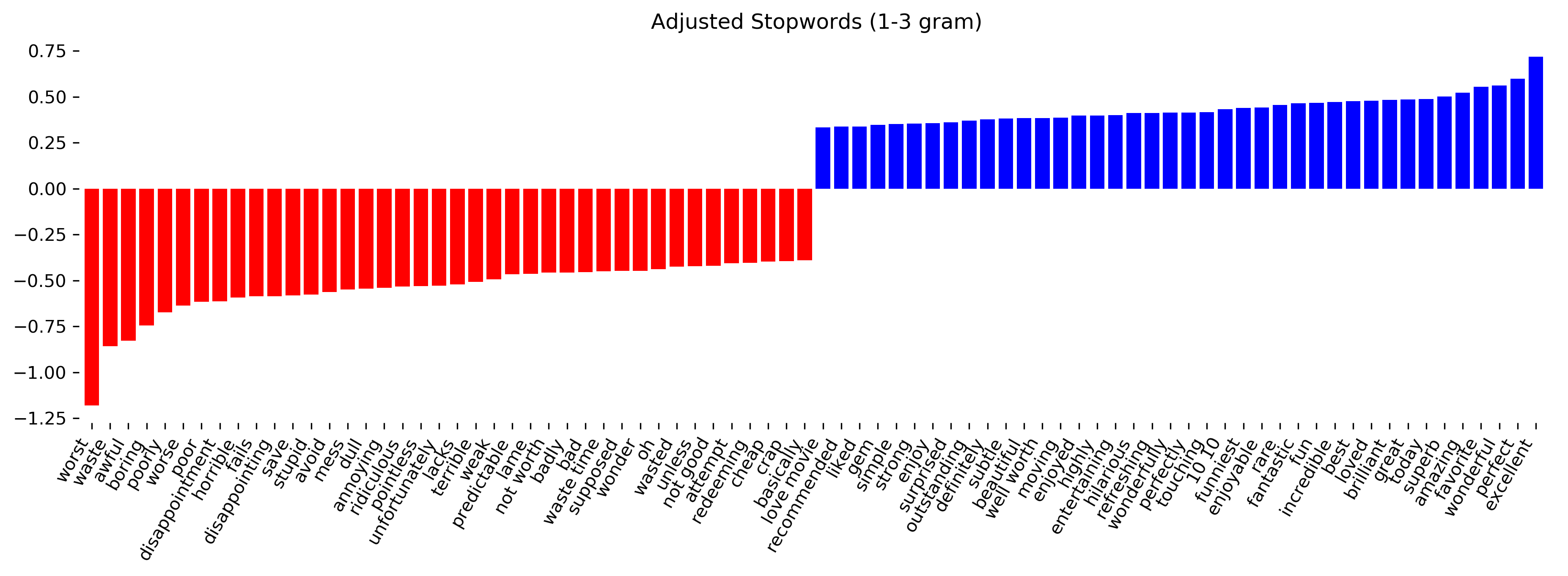 ] --- # Tf-idf rescaling $$ \text{tf-idf}(t,d) = \text{tf}(t,d)\cdot \text{idf}(t)$$ $$ \text{idf}(t) = \log\frac{1+n_d}{1+\text{df}(d,t)} + 1$$ $n_d$ = total number of documents <br/> $df(d,t)$ = number of documents containing term $t$ -- * In sklearn: by default also L2 normalisation! ??? * Emplasizes "rare" words - "soft stop word removal" * Slightly non-standard smoothing (many +1s) --- # TfidfVectorizer, TfidfTransformer .smaller[ ```python from sklearn.feature_extraction.text import TfidfVectorizer, TfidfTransformer ``` ```python malory_tfidf = TfidfVectorizer().fit_transform(malory) malory_tfidf.toarray() ``` ``` array([[ 0.41 , 0. , 0.576, 0. , 0. , 0. , 0.576, 0.41 ], [ 0.318, 0.447, 0. , 0.447, 0.447, 0.447, 0. , 0.318]]) ``` ```python malory_tfidf = make_pipeline(CountVectorizer(), TfidfTransformer()).fit_transform(malory) malory_tfidf.toarray() ``` ``` array([[ 0.41 , 0. , 0.576, 0. , 0. , 0. , 0.576, 0.41 ], [ 0.318, 0.447, 0. , 0.447, 0.447, 0.447, 0. , 0.318]]) ``` ] --- class: middle # Character n-grams --- #Principle <br> <br> .center[  ] --- #Principle <br> <br> .center[  ] --- #Principle <br> <br> .center[  ] --- #Principle <br> <br> .center[  ] --- #Principle <br> <br> .center[  ] --- class: spacious #Applications - Be robust to misspelling / obfuscation - Language detection - Learn from Names / made-up words --- # Toy example - "Naive" .tiny-code[ ```python cv = CountVectorizer(ngram_range=(2, 3), analyzer="char").fit(malory) print("Vocabulary size:", len(cv.vocabulary_)) print("Vocabulary:") print(cv.get_feature_names()) ``` ``` Vocabulary size: 73 Vocabulary: [' a', ' an', ' g', ' ge', ' h', ' ho', ' t', ' th', ' w', ' wa', ' y', ' yo', 'an', 'ant', 'at', 'at’', 'au', 'aus', 'be', 'bec', 'ca', 'cau', 'do', 'do ', 'e ', 'e t', 'ec', 'eca', 'et', 'et ', 'ge', 'get', 'ha', 'hat', 'ho', 'how', 'nt', 'nt ', 'nts', 'o ', 'o y', 'ou', 'ou ', 'ow', 'ow ', 's ', 's h', 's.', 's?', 'se', 'se ', 't ', 't a', 'th', 'tha', 'ts', 'ts.', 'ts?', 't’', 't’s', 'u ', 'u g', 'u w', 'us', 'use', 'w ', 'w y', 'wa', 'wan', 'yo', 'you', '’s', '’s '] ``` ] - Respect word boundaries .tiny-code[ ```python cv = CountVectorizer(ngram_range=(2, 3), analyzer="char_wb").fit(malory) print("Vocabulary size:", len(cv.vocabulary_)) print("Vocabulary:") print(cv.get_feature_names()) ``` ``` Vocabulary size: 74 Vocabulary: [' a', ' an', ' b', ' be', ' d', ' do', ' g', ' ge', ' h', ' ho', ' t', ' th', ' w', ' wa', ' y', ' yo', '. ', '? ', 'an', 'ant', 'at', ' at’', 'au', 'aus', 'be', 'bec', 'ca', 'cau', 'do', 'do ', 'e ', 'ec', 'eca', 'et', 'et ', 'ge', 'get', 'ha', 'hat', 'ho', 'how', 'nt', 'nt ', 'nts', 'o ', 'ou', 'ou ', 'ow', 'ow ', 's ', 's.', 's. ', 's?', 's? ', 'se', 'se ', 't ', 'th', 'tha', 'ts', 'ts.', 'ts?', 't’', 't’s', 'u ', 'us', 'use', 'w ', 'wa', 'wan', 'yo', 'you', '’s', '’s '] ``` ] --- # IMDB Data .smaller[ ```python char_vect = CountVectorizer(ngram_range=(2, 5), min_df=4, analyzer="char_wb") X_train_char = char_vect.fit_transform(text_train) ``` ```python len(char_vect.vocabulary_) ``` ``` 164632 ``` ```python lr_char = LogisticRegressionCV().fit(X_train_char, y_train) X_val_char = char_vect.transform(text_val) lr_char.score(X_val_char, y_val) ``` ``` 0.881 ``` ] --- class: middle .center[  ] --- class: middle # Predicting Nationality from Name --- .center[  ] .center[ 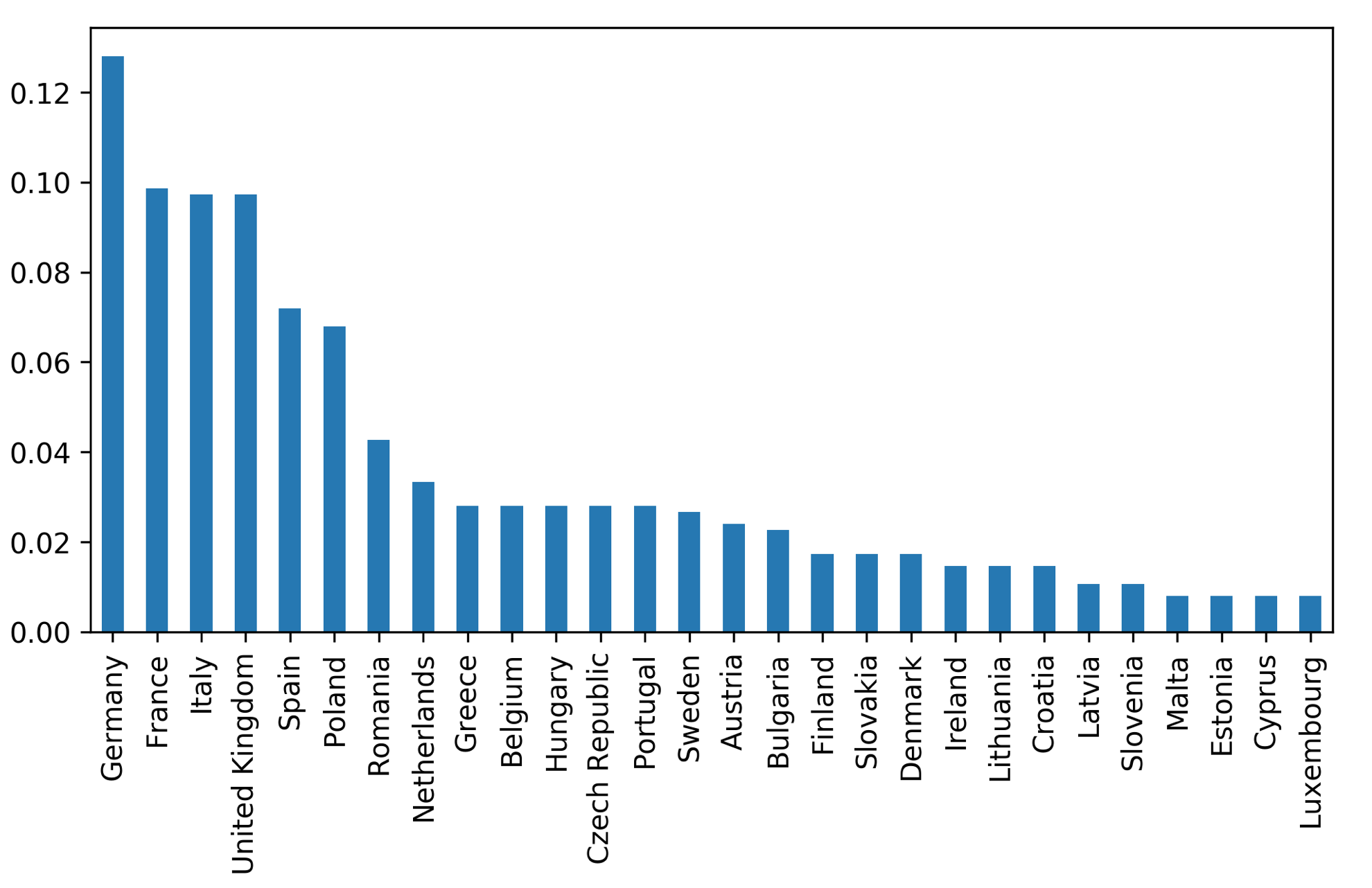 ] --- # Comparing words vs chars .tiny-code[ ```python bow_pipe = make_pipeline(CountVectorizer(), LogisticRegressionCV()) cross_val_score(bow_pipe, text_mem_train, y_mem_train, cv=5, scoring='f1_macro') ``` ``` array([ 0.231, 0.241, 0.236, 0.28 , 0.254]) ``` ```python char_pipe = make_pipeline(CountVectorizer(analyzer="char_wb"), LogisticRegressionCV()) cross_val_score(char_pipe, text_mem_train, y_mem_train, cv=5, scoring='f1_macro') ``` ``` array([ 0.452, 0.459, 0.341, 0.469, 0.418]) ``` ] --- # Grid-search parameters .tiny-code[ ```python from sklearn.model_selection import GridSearchCV from sklearn.linear_model import LogisticRegression from sklearn.preprocessing import Normalizer param_grid = {"logisticregression__C": [100, 10, 1, 0.1, 0.001], "countvectorizer__ngram_range": [(1, 1), (1, 2), (1, 5), (1, 7), (2, 3), (2, 5), (3, 8), (5, 5)], "countvectorizer__min_df": [1, 2, 3], "normalizer": [None, Normalizer()] } grid = GridSearchCV(make_pipeline(CountVectorizer(analyzer="char"), Normalizer(), LogisticRegression(), memory="cache_folder"), param_grid=param_grid, cv=10, scoring="f1_macro" ) ``` ```python grid.fit(text_mem_train, y_mem_train) ``` ```python grid.best_score_ ``` ``` 0.58255198397046815 ``` ```python grid.best_params_ ``` ``` {'countvectorizer__min_df': 2, 'countvectorizer__ngram_range': (1, 5), 'logisticregression__C': 10} ``` ] ??? - Small dataset, makes grid-search faster! (less reliable) --- .center[ 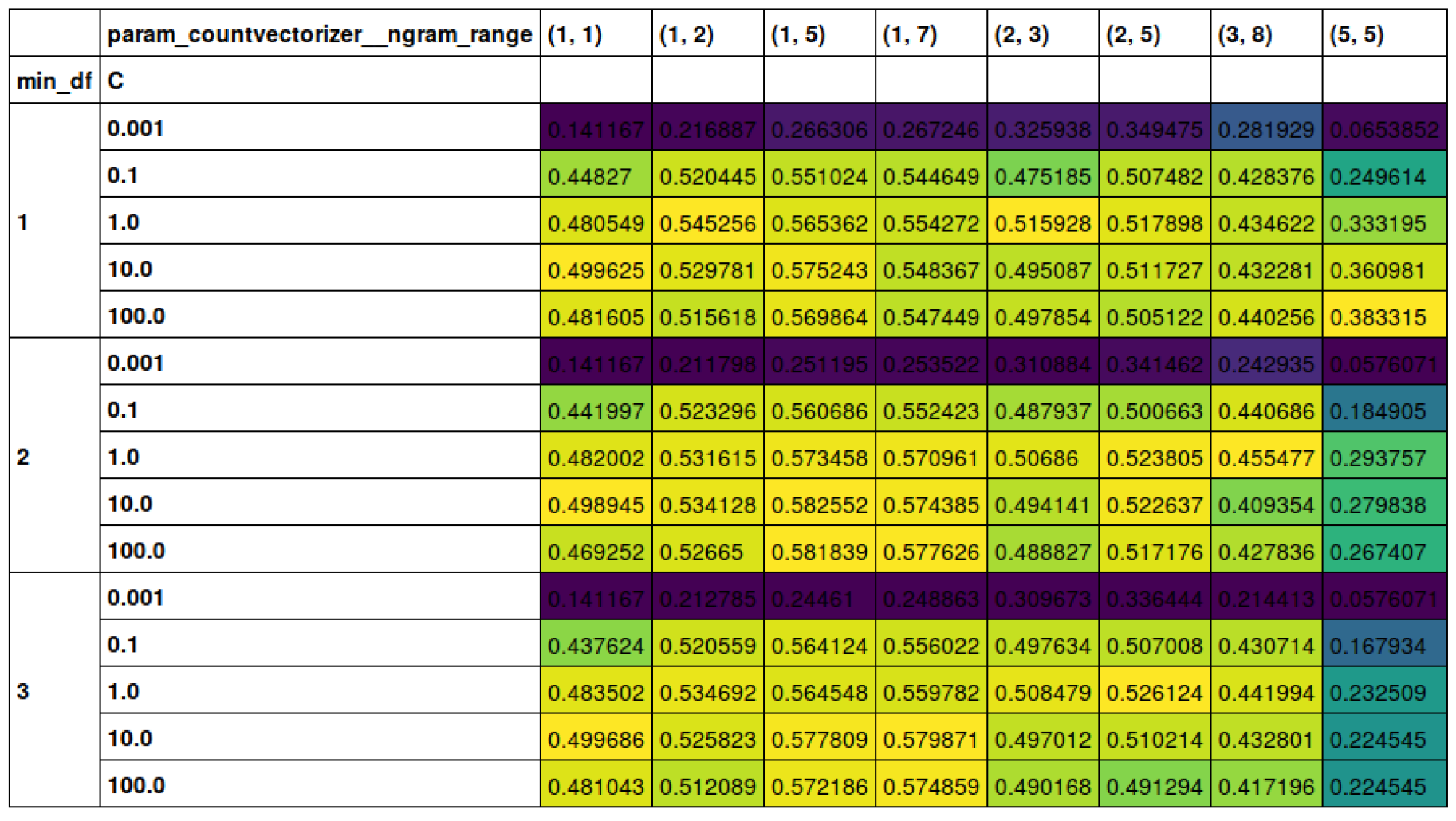 ] --- # Other features - Length of text - Number of out-of-vocabularly words - Presence / frequency of ALL CAPS - Punctuation...!? (somewhat captures by char ngrams) - Sentiment words (good vs bad) - Whatever makes sense for the task! --- class: middle # Large Scale Text Vectorization --- .center[  ] --- .center[ 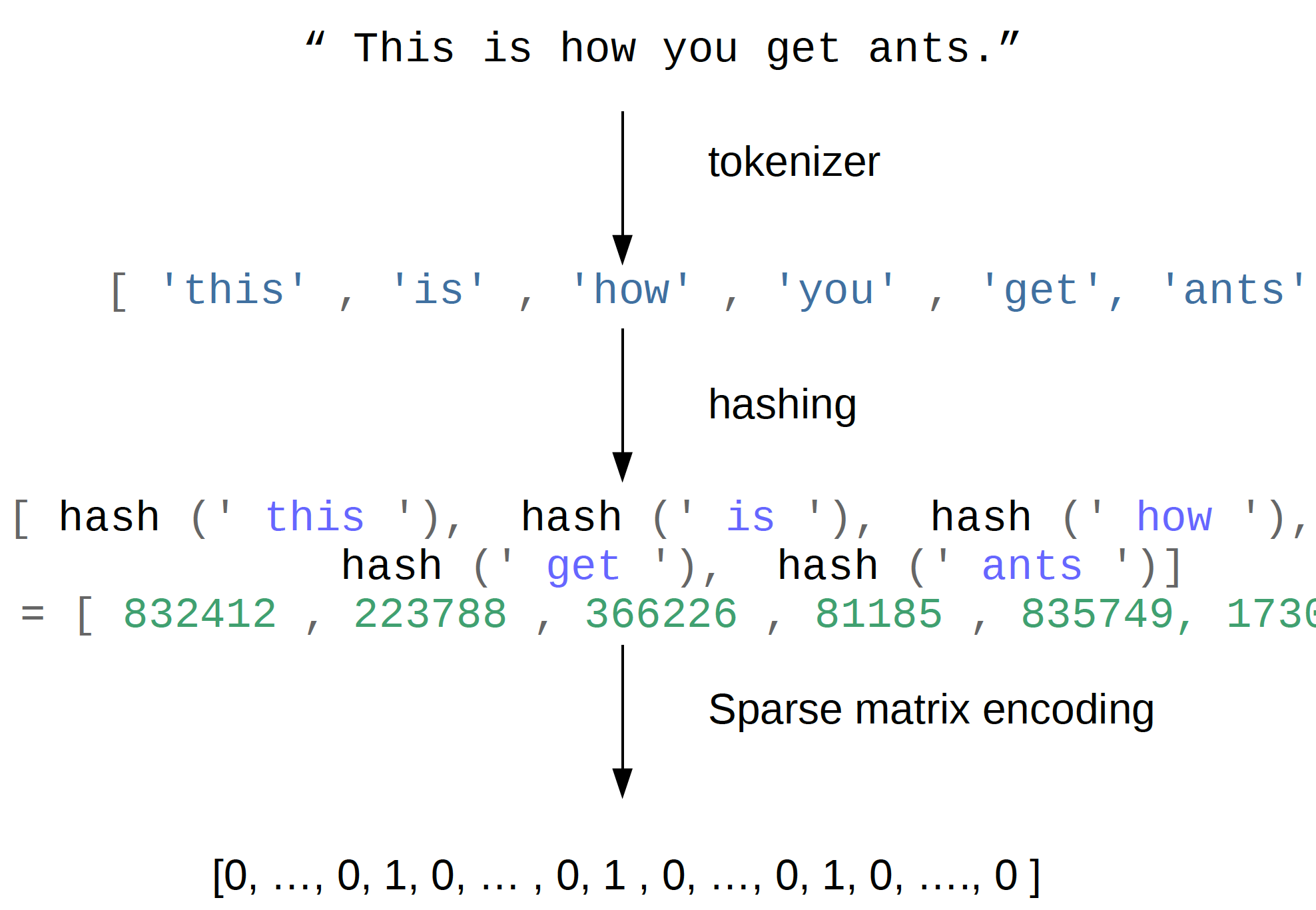 ] --- # Near drop-in replacement .smallest[ - Careful: Uses l2 normalization by default! ] .tiny-code[ ```python from sklearn.feature_extraction.text import HashingVectorizer hv = HashingVectorizer() X_train = hv.transform(text_train) X_val = hv.transform(text_val) ``` ```python lr.score(X_val, y_val) ``` ```python from sklearn.feature_extraction.text import HashingVectorizer hv = HashingVectorizer() X_train = hv.transform(text_train) X_val = hv.transform(text_val) ``` ```python X_train.shape ``` ``` (18750, 1048576) ``` ```python lr = LogisticRegressionCV().fit(X_train, y_train) lr.score(X_val, y_val) ``` ] --- # Trade-offs .left-column[ Pro: - Fast - Works for streaming data - Low memory footprint ] .right-column[ Con: - Can't interpret results - Hard to debug - (collisions are not a problem for performance) ] --- class: middle # Questions ?