class: center, middle  ### Introduction to Machine learning with scikit-learn # Gradient Boosting Andreas C. Müller Columbia University, scikit-learn .smaller[https://github.com/amueller/ml-training-intro] --- ??? We'll continue tree-based models, talking about boosting. Another ensemble technique called stacking. Finally, a technique called calibration that looks somewhat similar to ensembles but has the goal of obtaining good probability estimates from any classifier. FIXME: XGBOOST!! FIXME early stopping FIXME GBRT: better explain log-loss FIXME: add example of calibrated and inaccurate vs accurate but not calibrated! FIXME: calibration: what are the estimators fit to, and why does fitting it to 0 and 1 create probabilities in between Partial dependence plot. how is that different from feature importances. calibration curve plotting: bins are different for hist and calibration curve? slide 27: maybe put probabilities on x axis? calibration curve: blue histogram is number of total points, y axis not labeled --- class: centre,middle # Gradient Boosting ??? Gradient boosting is one of the most successfull supervised machine learning methods in practice. It's often used in kaggle to win competition, it's used for credit scoring, it's one of the standard tools of the trade. It's one of the best of-the-shelf models A standard implementation that people use is XGBoost, but there's also an implementation in scikit-learn, and we'll talk about both of them. Last time we talked about Random forests, which builds many trees independently, each randomized in a different way, and then averages their predictions. Gradient boosting on the other hand builds trees one by one in a sequential manner, with each tree requiring the results of previous trees. Often, Gradient boosting is done with very small trees, or even decision stumps, which is trees of depth one, so a single split. --- class: center, middle # Boosting (in General) ??? - “Meta-algorithm” to create strong learners from weak learners. - AdaBoost, GentleBoost, … - Trees or stumps work best - Gradient Boosting often the best of the bunch - Many specialized algorithms (ranking etc) This is an instance of a more general family of models, called boosting models, which all iteratively try to improve a model built up from weak learners. Gradient boosting is this particular technique where we are trying to fit the residuals, and it's been found to work very well in practice, in particular if you're using shallow trees as the weak learners. In principle, you could use any model as a weak learner, but trees just work really well. --- # Gradient Boosting Algorithm `$$ f_{1}(x) \approx y $$` `$$ f_{2}(x) \approx y - f_{1}(x) $$` `$$ f_{3}(x) \approx y - f_{1}(x) - f_{2}(x)$$` -- $y \approx$  +  +  + ... ??? Let's look at the regression case first. We start by building a single tree f1 to try to predict the output y. But we strongly restrict f1, so it will be rather bad at predicting y. Next, we'll look at the residual of this first model, so y - f1(x). We now train a new model f2 to try and predict this residual, in other words to correct the mistakes made by f1. Again, this will be a very simple model, so it will still not be able to fix all errors. Then, we look at the residual of both of the models together, so y - f1(x) - f2(x), so the mistakes that could not be fixed by f2, and we build f3 to fix that, and so on. This is natural for regression. For classification this is not as clear. For binary classification you use log-loss, or rather you apply the logistic function to get a binary prediction, for multi-class you can use 1 vs rest. So we're sequentially building up a model using what's called "weak learners", small trees, and create a more powerful composite model. --- # Gradient Boosting Algorithm `$$ f_{1}(x) \approx y $$` `$$ f_{2}(x) \approx y - \alpha f_{1}(x) $$` `$$ f_{3}(x) \approx y - \alpha f_{1}(x) - \alpha f_{2}(x)$$` $y \approx \alpha$  + $\alpha$  + $\alpha$  + ... <br /> <br /> Learning rate $\alpha, i.e. 0.1$ ??? - Iteratively add regression trees to model - Use log loss for classification - Discount update by learning rate FIXME plot for regression models Come back to this --- #GradientBoostingRegressor .center[  ] ??? --- #GradientBoostingClassifier .center[ 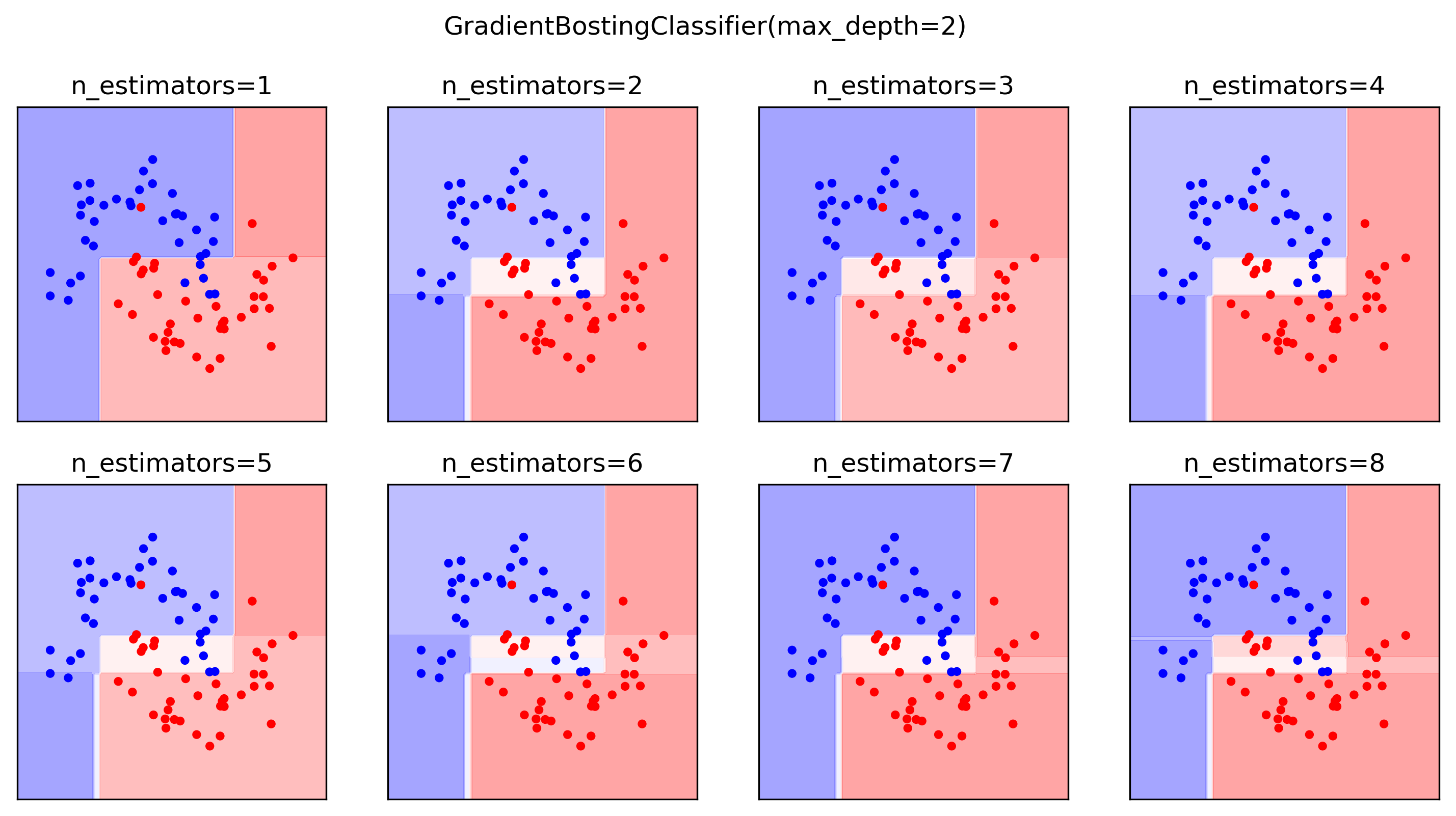 ] ??? --- class:spacious # Gradient Boosting Advantages - Slower to train than RF (serial), but much faster to predict - Small model size - Typically more accurate than Random Forests ??? --- class:spacious # Tuning Gradient Boosting - Pick n_estimators, tune learning rate - Can also tune max_features - Typically strong pruning via max_depth ??? --- # Partial Dependence Plots - Marginal dependence of prediction on one or two features .smaller[ ```python from sklearn.ensemble.partial_dependence import plot_partial_dependence boston = load_boston() X_train, X_test, y_train, y_test = train_test_split( boston.data, boston.target,random_state=0) gbrt = GradientBoostingRegressor().fit(X_train, y_train) fig, axs = plot_partial_dependence( gbrt, X_train, np.argsort(gbrt.feature_importances_)[-6:], feature_names=boston.feature_names, n_jobs=3, grid_resolution=50) ``` ] ??? --- # Partial Dependence Plots .center[ 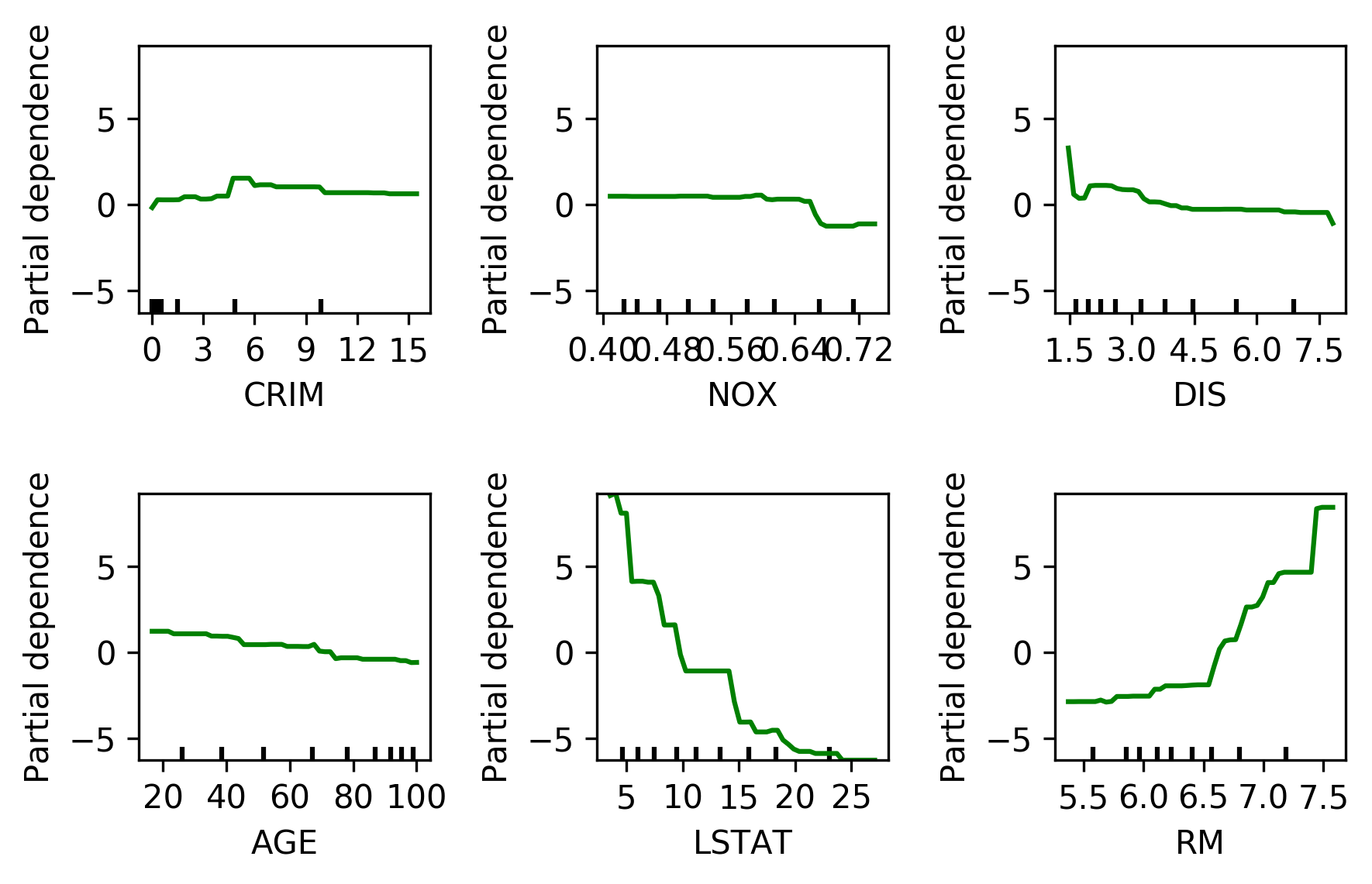 ] ??? --- # Bivariate Partial Dependence Plots .smaller[ ```python plot_partial_dependence( gbrt, X_train, [np.argsort(gbrt.feature_importances_)[-2:]], feature_names=boston.feature_names, n_jobs=3, grid_resolution=50) ``` ] .center[ 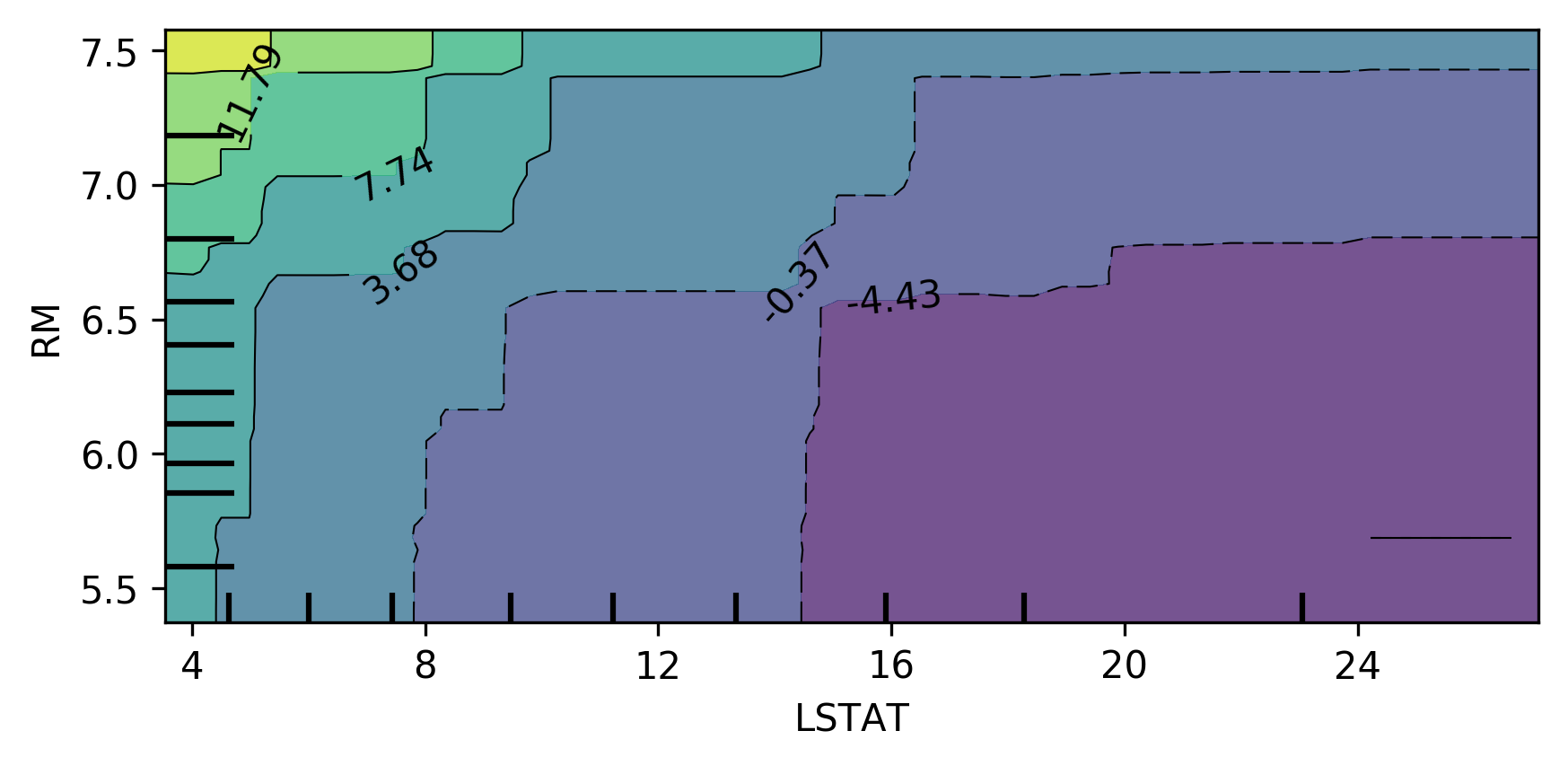 ] ??? --- # Partial Dependence for Classification .tiny-code[ ```python from sklearn.ensemble.partial_dependence import plot_partial_dependence for i in range(3): fig, axs = plot_partial_dependence(gbrt, X_train, range(4), n_cols=4, feature_names=iris.feature_names, grid_resolution=50, label=i) ``` ] .center[ 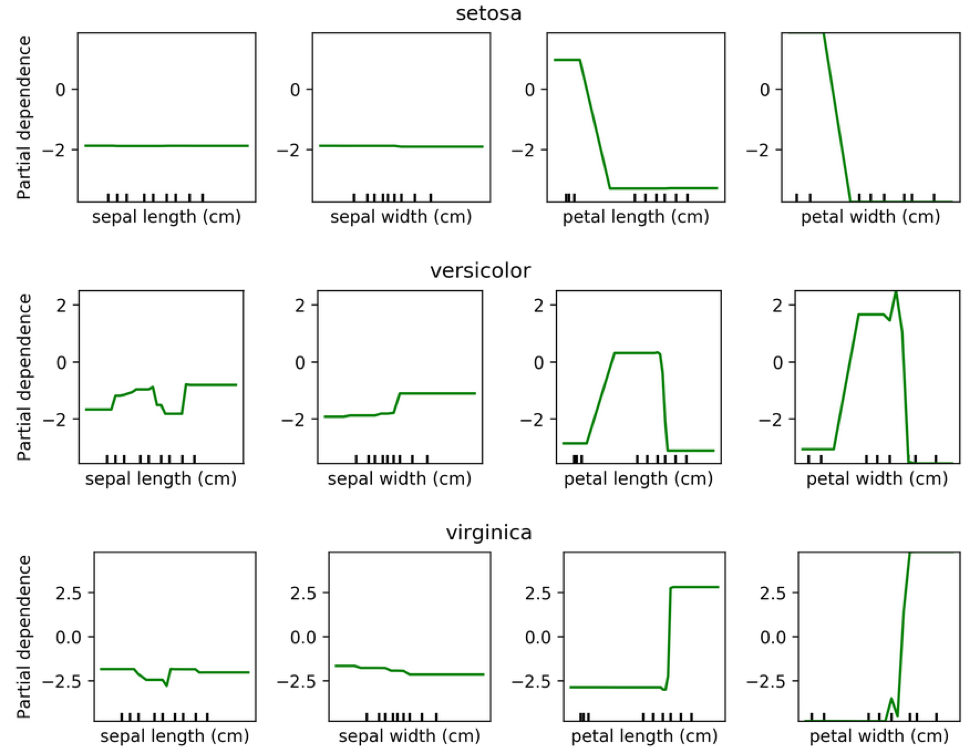 ] ??? --- # XGBoost `conda install -c conda-forge xgboost` ```python from xgboost import XGBClassifier xgb = XGBClassifier() xgb.fit(X_train, y_train) xgb.score(X_test, y_test)) ``` - supports missing values - supports multi-core ??? - Efficient implementation of gradient boosting (5x sklearn) - Improvements on original algorithm - https://arxiv.org/abs/1603.02754 - Adds l1 and l2 penalty on leaf-weights - Fast approximate split finding - Scikit-learn compatible interface --- class: spacious .center[  ] - Exact splits ~5x faster on single core - Appoximate splits, multi-core -> more speed! - Also check lightGBM (even faster?) - Both have GPU support - https://github.com/szilard/GBM-perf ??? --- # Early stopping - Adding trees can lead to overfitting - Stop adding trees when validation accuracy stops increasing - Optional in XGBoost and sklearn >= 0.20 (development) ??? --- class:spacious # When to use tree-based models - Model non-linear relationships - Doesn’t care about scaling, no need for feature engineering - Single tree: very interpretable (if small) - Random forests very robust, good benchmark - Gradient boosting often best performance with careful tuning