class: center, middle  ### Advanced Machine Learning with scikit-learn Part I/II # Reminder: Scikit-learn API Andreas C. Müller Columbia University, scikit-learn .smaller[https://github.com/amueller/ml-workshop-3-of-4] --- class: center # scikit-learn documentation  <a href="http://scikit-learn.org/" style="color:black; font-size:50px; text-decoration:None" >scikit-learn.org</a> --- # Other Resources .center[    ] Lecture: http://www.cs.columbia.edu/~amueller/comsw4995s19/schedule/ https://www.youtube.com/andreasmueller Videos and more slides! --- class: center # Representing Data  --- class: center # Supervised ML Workflow  --- # KNN with scikit-learn ```python from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y) from sklearn.neighbors import KNeighborsClassifier knn = KNeighborsClassifier(n_neighbors=1) knn.fit(X_train, y_train) print("accuracy: ", knn.score(X_test, y_test))) y_pred = knn.predict(X_test) ``` accuracy: 0.77 ??? --- class: center, middle # Sckit-Learn API Summary  --- class: center, spacious # Overfitting and Underfitting 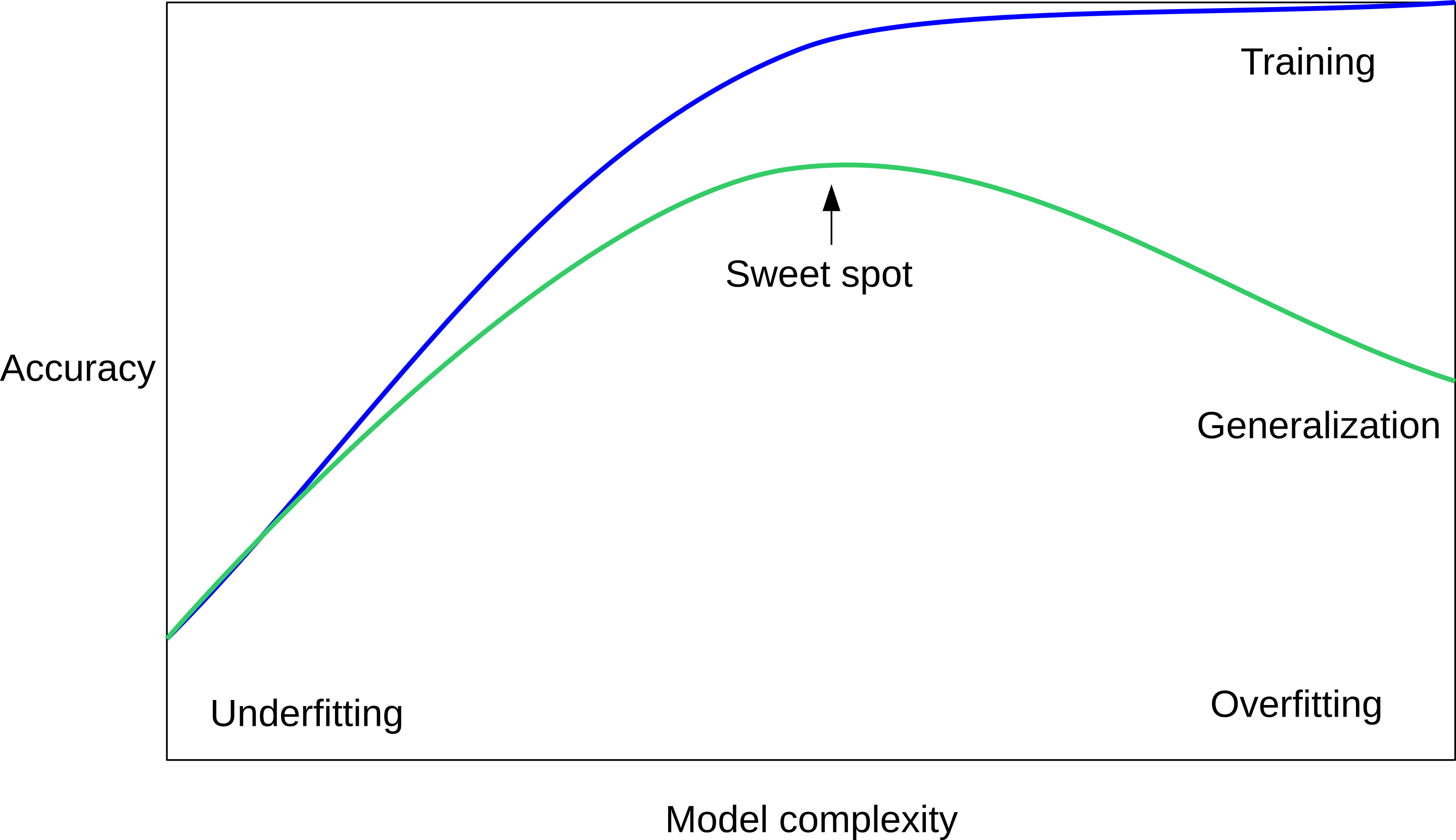 ??? If we use too simple a model, this is often called underfitting, while if we use to complex a model, this is called overfitting. And somewhere in the middle is a sweet spot. Most models have some way to tune model complexity, and we’ll see many of them in the next couple of weeks. So going back to nearest neighbors, what parameters correspond to high model complexity and what to low model complexity? high n_neighbors = low complexity! --- class: center, some-space # Cross-validation + test set 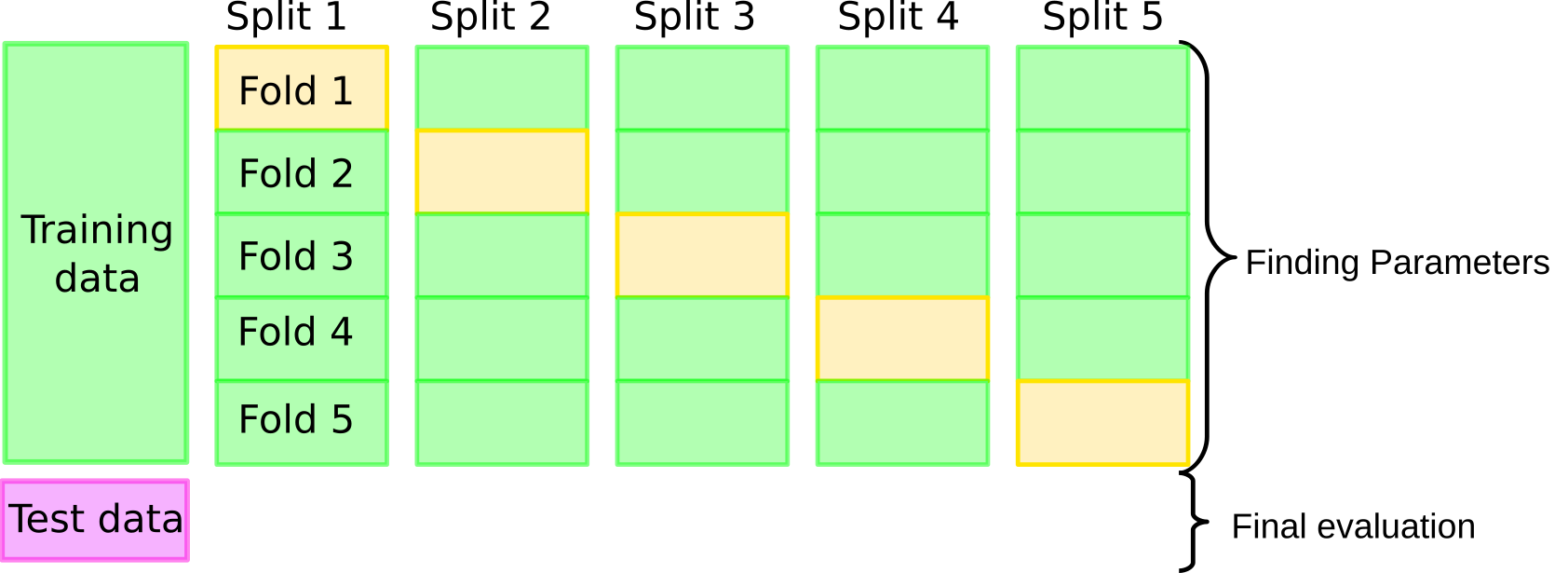 ??? Here is how the workflow looks like when we are using five-fold cross-validation together with a test-set split for adjusting parameters. We start out by splitting of the test data, and then we perform cross-validation on the training set. Once we found the right setting of the parameters, we retrain on the whole training set and evaluate on the test set. --- class: center, middle 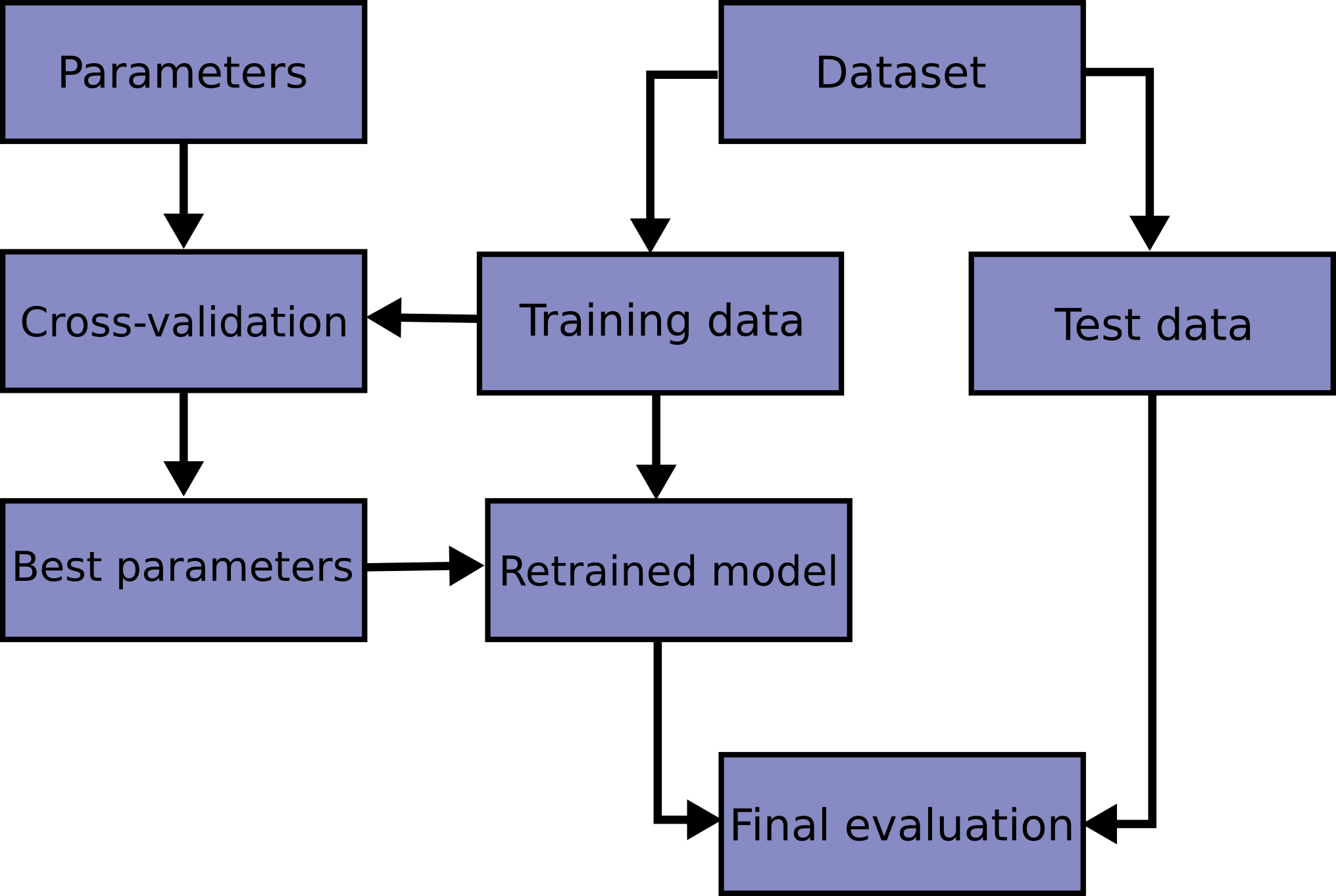 ??? Here is a conceptual overview of this way of tuning parameters, we start of with the dataset and a candidate set of parameters we want to try, labeled parameter grid, for example the number of neighbors. We split the dataset in to training and test set. We use cross-validation and the parameter grid to find the best parameters. We use the best parameters and the training set to build a model with the best parameters, and finally evaluate it on the test set. Because this is such a common pattern, there is a helper class for this in scikit-learn, called GridSearch CV, which does most of these steps for you. --- # GridSearchCV .smaller[ ```python from sklearn.model_selection import GridSearchCV X_train, X_test, y_train, y_test = train_test_split(X, y, stratify=y) param_grid = {'n_neighbors': np.arange(1, 30, 2)} grid = GridSearchCV(KNeighborsClassifier(), param_grid=param_grid, cv=10, return_train_score=True) grid.fit(X_train, y_train) print(f"best mean cross-validation score: {grid.best_score_}") print(f"best parameters: {grid.best_params_}") print(f"test-set score: {grid.score(X_test, y_test):.3f}") ``` ``` best mean cross-validation score: 0.967 best parameters: {'n_neighbors': 9} test-set score: 0.993 ``` ] ??? Here is an example. We still need to split our data into training and test set. We declare the parameters we want to search over as a dictionary. In this example the parameter is just n_neighbors and the values we want to try out are a range. The keys of the dictionary are the parameter names and the values are the parameter settings we want to try. If you specify multiple parameters, all possible combinations are tried. This is where the name grid-search comes from - it’s an exhaustive search over all possible parameter combinations that you specify. GridSearchCV is a class, and it behaves just like any other model in scikit-learn, with a fit, predict and score method. It’s what we call a meta-estimator, since you give it one estimator, here the KneighborsClassifier, and from that GridSearchCV constructs a new estimator that does the parameter search for you. You also specify the parameters you want to search, and the cross-validation strategy. Then GridSearchCV does all the other things we talked about, it does the cross-validation and parameter selection, and retrains a model with the best parameter settings that were found. We can check out the best cross-validation score and the best parameter setting with the best_score_ and best_params_ attributes. And finally we can compute the accuracy on the test set, simply but using the score method! That will use the retrained model under the hood.