class: center, middle  ### Introduction to Machine learning with scikit-learn # Cross Validation and Grid Search Andreas C. Müller Columbia University, scikit-learn .smallest[https://github.com/amueller/ml-workshop-short] --- # So far: train-test split 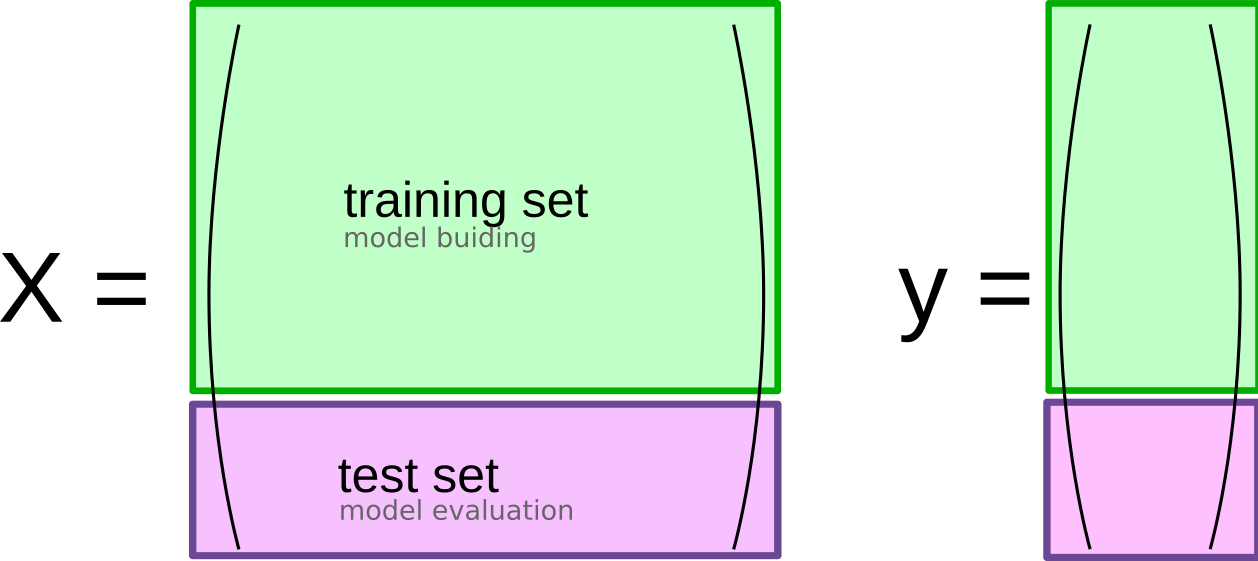 ??? --- # Better: Threefold split 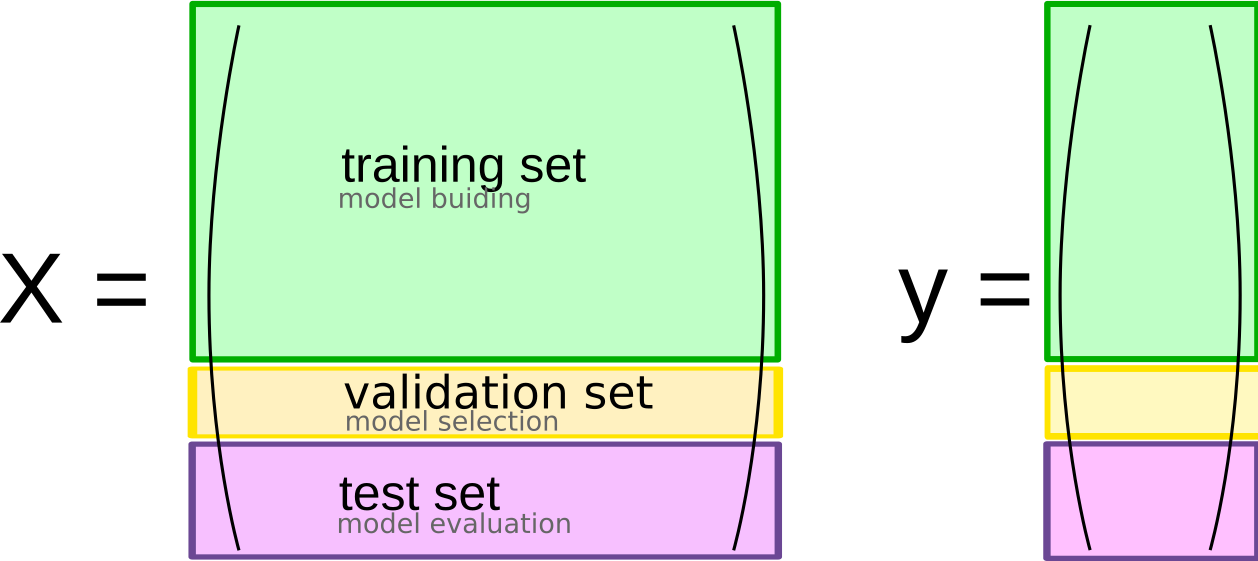 ??? The simplest way to combat this overfitting to the test set is by using a three-fold split of the data, into a training, a validation and a test set as we just did. We use the training set for model building, the validation set for parameter selection and the test set for a final evaluation of the model. So how many models should you try out on the test set? Only one! Ideally use use the test-set exactly once, otherwise you make a multiple hypothesis testing error! What are downsides of this? We lose a lot of data for evaluation, and the results depend on the particular sampling. pro: fast, simple con: high variance, bad use of data --- # Decrease Variance: Cross-validation <br /> .center[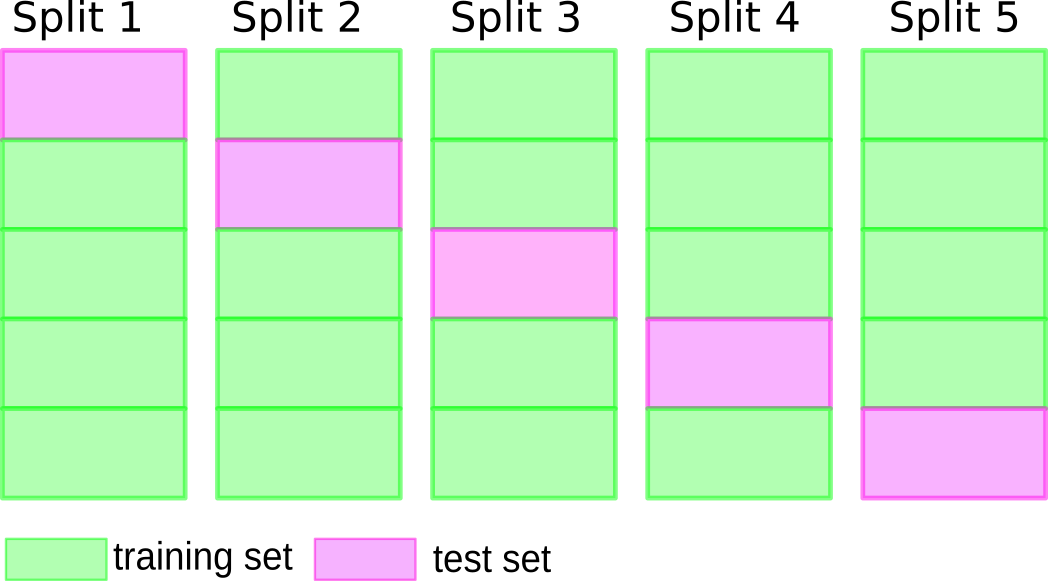] ??? The answer is of course cross-validation. In cross-validation, you split your data into multiple folds, usually 5 or 10, and built multiple models. You start by using fold1 as the test data, and the remaining ones as the training data. You build your model on the training data, and evaluate it on the test fold. For each of the splits of the data, you get a model evaluation and a score. In the end, you can aggregate the scores, for example by taking the mean. What are the pros and cons of this? Each data point is in the test-set exactly once! Takes 5 or 10 times longer! Better data use (larger training sets). Does that solve all problems? No, it replaces only one of the splits, usually the inner one! pro: more stable, more data con: slower ??? --- class: center, some-space # Cross-validation + test set 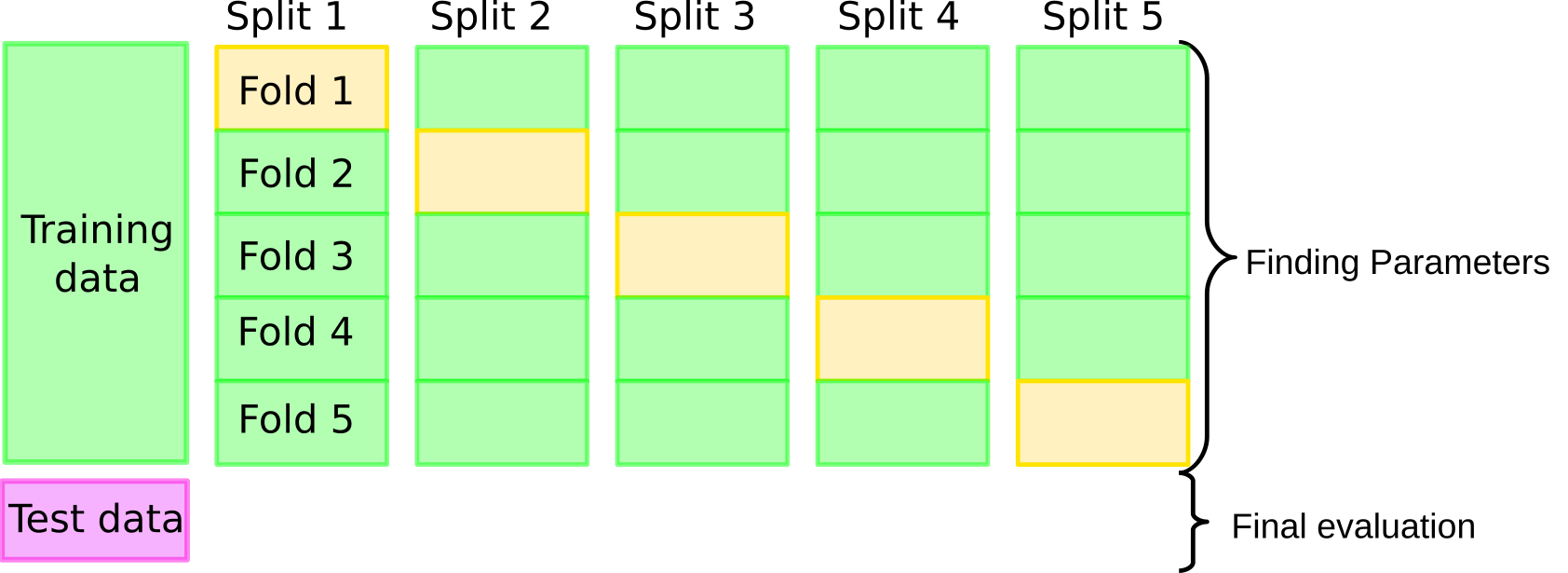 ??? Here is how the workflow looks like when we are using five-fold cross-validation together with a test-set split for adjusting parameters. We start out by splitting of the test data, and then we perform cross-validation on the training set. Once we found the right setting of the parameters, we retrain on the whole training set and evaluate on the test set. --- class: center, middle 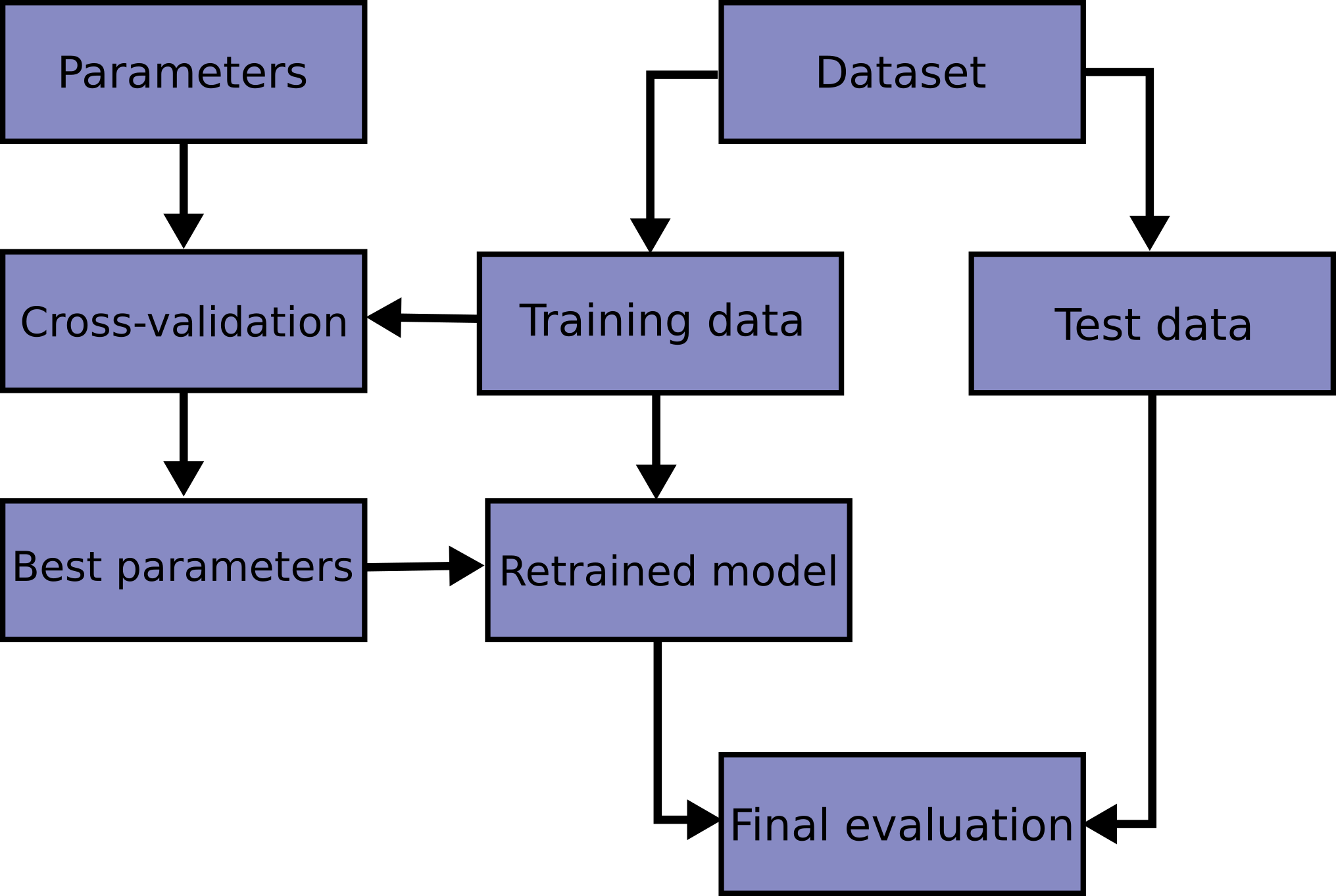 ??? Here is a conceptual overview of this way of tuning parameters, we start of with the dataset and a candidate set of parameters we want to try, labeled parameter grid, for example the number of neighbors. We split the dataset in to training and test set. We use cross-validation and the parameter grid to find the best parameters. We use the best parameters and the training set to build a model with the best parameters, and finally evaluate it on the test set. Because this is such a common pattern, there is a helper class for this in scikit-learn, called GridSearch CV, which does most of these steps for you. --- # GridSearchCV .smaller[ ```python from sklearn.model_selection import GridSearchCV X_train, X_test, y_train, y_test = train_test_split(X, y, stratify=y) param_grid = {'n_neighbors': np.arange(1, 15, 2)} grid = GridSearchCV(KNeighborsClassifier(), param_grid=param_grid, cv=10, return_train_score=True) grid.fit(X_train, y_train) print("best mean cross-validation score: {:.3f}".format(grid.best_score_)) print("best parameters: {}".format(grid.best_params_)) print("test-set score: {:.3f}".format(grid.score(X_test, y_test))) ``` ``` best mean cross-validation score: 0.967 best parameters: {'n_neighbors': 9} test-set score: 0.993 ``` ] ??? Here is an example. We still need to split our data into training and test set. We declare the parameters we want to search over as a dictionary. In this example the parameter is just n_neighbors and the values we want to try out are a range. The keys of the dictionary are the parameter names and the values are the parameter settings we want to try. If you specify multiple parameters, all possible combinations are tried. This is where the name grid-search comes from - it’s an exhaustive search over all possible parameter combinations that you specify. GridSearchCV is a class, and it behaves just like any other model in scikit-learn, with a fit, predict and score method. It’s what we call a meta-estimator, since you give it one estimator, here the KneighborsClassifier, and from that GridSearchCV constructs a new estimator that does the parameter search for you. You also specify the parameters you want to search, and the cross-validation strategy. Then GridSearchCV does all the other things we talked about, it does the cross-validation and parameter selection, and retrains a model with the best parameter settings that were found. We can check out the best cross-validation score and the best parameter setting with the best_score_ and best_params_ attributes. And finally we can compute the accuracy on the test set, simply but using the score method! That will use the retrained model under the hood. --- class: center # n_neighbors Search Results 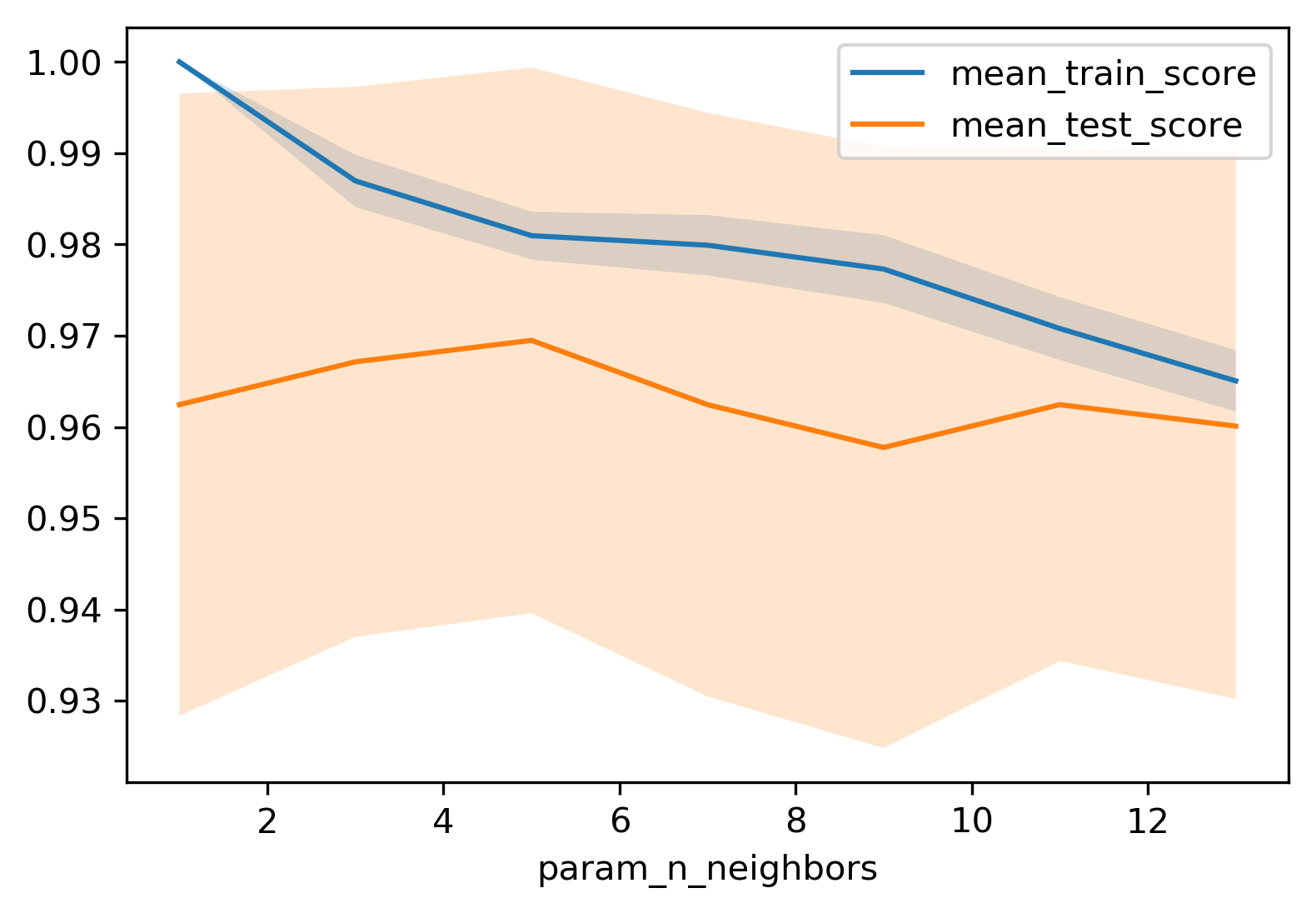 ??? We can use this for example to plot the results of cross-validation over the different parameters. Here are the mean training score and mean test score together with one standard deviation. --- class: center, middle # Notebook: Cross-validation and grid search