Linear Models for Regression¶
One of the oldest and most widely used models are linear regression models. Linear models for regression have been a staple in statistics and engineering long before the invention of the terms Computer Science and Machine Learning TODO cite. In fact, one of the most commonly used approaches goes back to Gauss himself, and you might have seen some variant of it in high school. Linear models for regression also serve as the basis for the linear models for classification that we will see in section TODO.
The principle of linear models is illustrated in Figure TODO which shows a linear regression in one dimension, in our terminology we have one feature, shown on the x-axis, and our target is shown on the y-axis. We now try to find a linear relationship between the two, in other words, we want to find a straight line that is as close as possible to all of the points. For a single feature, you can write the prediction given by the line as \($ \hat{y} = a x + b $\) where \(a\) and \(b\) are fixed numbers, and \(x\) is the value of our input feature. Here, \(a\) is the slope of the line, and \(b\) is known as the intercept or offset. It is the place where the fitted line crossed the y-axis. For more than one feature, the prediction takes the form \($ \hat{y} = w_1 x_1 + w_2 x_2 + ... + w_p x_p + b $\) where \(x_1\) to \(x_p\) are the features (i.e. we have p features) and \(w_1\) to \(w_p\) are the coefficients or slope for each of these features. For more than one features, visualizing the prediction is much trickier, so we’ll skip that for now.
Mathematical details
Often the above equation is written as as an inner product between two vectors \(w \in \mathbb{R}^p\) and \(x\in \mathbb{R}^p\): \($\hat{y} = w^T \mathbf{x} + b = \sum_{i=1}^p w_i x_i +b\)$ As a side note, linear models are named such because they are linear in \(w\), not because they are linear in \(x\). In fact, we can replace any \(x_i\) by an arbitrary fixed function of \(x\), say \(sin(x_i)\) or \(x_i * x_j\), and it would still be considered a linear model. This is one of the powers of this kind of model, and we’ll discuss it in more depth in chapter TODO feature engineering.
All linear models for regression share the same formular for prediction shown in TODO. However, how they differ is in how they learn the coefficients \(w\) and \(b\) from the training data. Here, \(w\) and \(b\) are parameters of the model (in the statistical sense), i.e. they are the parts of the model that are estimated from the training data. Nearly all of the methods for learning linear models are formulated as an optimization problem, where the goal is to find the optimum of some mathematical formula, which is known as objective function. We will provide the objective functions (and therefore the optimizatio problem) that give rise to all the models we will discuss. If you are not familiar with optimization, you can skip these parts as we will also provide some more intuitive explanation of each method.
Ordinary Least Squares¶
The oldest and probably the most widely use method to learn the parameters \(w\) and \(b\) is ordinary least squares (OLS). This is what people usually refer to when they say “linear regression” and it’s what’s implemented in scikit-learn’s LinearRegression class. The idea behind OLS is to compute the least squares solution, which means find the parameters \(w\) and \(b\) so that the prediction error on the training set has the smallest possible squared norm.
This is a classical and well-understood method. However, it requires the training data to be somewhat well-behaved. If there are more features than there are samples, or if there is a linear relationship between the features, then the method can be unstable and will often reduce non-sensical results.
TODO image
Mathematical details
The objective function of ordinary least squares for linear regression is given by \($\min_{w \in \mathbb{R}^p, b\in\mathbb{R}} \sum_{i=1}^n (w^T\mathbf{x}_i + b - y_i)^2\)$ Here, $x_i, i=1,…,n $ are the training vectors and \(y_i i=1,...,n\) TODO indexing unlike above?! are the corresponding targets. The formula on the right computes the prediction error for each training sample, squares it, and then sums over all the samples. The outcome is a number that measures the euclidean length (aka squared norm) of the error \(\hat{y}_i - y_i\). We want to find a vector \(w\) and a number \(b\) such that this error is minimized. If the data matrix X has full column rank, then this is a convex optimization problem, and we can easily compute the optimum with a number of standard techniques. If the data matrix X does not have full column rank, for example if there is more feature than samples, then there is no unique optimum; in fact there will be infinitely many solutions that lead to zero error on the training set. In this case, the optimization problem is called ill conditioned as no unique solution exists. In this case we can add additional criteria that guarantee a well-behaved solution TODO ref, though they are not always implemented in statistical software.
Before we look at examples of using LinearRegression let’s look at an alternative that is particularly popular for predictive modelling, Ridge Regression
Ridge Regression¶
Ridge regression is an extension to OLS in which we add another demand to our solution. Not only do we want our model to fit the training data well, we also want it to be simple.
We already discussed in chapter TODO, that we prefer simple solutions, as they will generalize more readily to new data. TODO this needs work.
We can include this directly in our modeling process-however, we have to formalize what we mean by “simple”. In Ridge regression, simple is encoded as having small slope in all directions.
In other words, we want our coefficient vectors \(w\) to be as close as possible to 0 (in fact the restriction is on \(w^2\)). So now we have to goals: we want a simple model (i.e. one with small coefficients) that also fits the training data well. To allow optimizing both, we need to introduce a parameter, often called \(\alpha\) (or sometimes \(\lambda\)) that trades off between the two goals. Now \(\alpha\) is a hyper-parameter that we need to tune or pick, say using GridSearchCV. Setting \(alpha=0\) will disregard the simplicity demand, and is equivalent to using OLS. Setting \(\alpha=\infty\) will basically disregard the data fitting demand, and will produce a coefficient vector of all zeros, which is the most “simple” solution according to the least squares measure used in Ridge regression. The \(\alpha\) parameter is known as regularization parameter or penalty term, as it regularizes or penalizes overly complex solutions \(w\).
Mathematical details
The objective function of Ridge regression is very similar to OLS; it only has the addition of the penalty term \(\alpha ||w||^2\). Notice that the intercept \(b\) is not penalized. TODO explain? \($ \min_{w \in \mathbb{R}^p, b\in\mathbb{R}} \sum_{i=1}^n (w^T\mathbf{x}_i + b - y_i)^2 + \alpha ||w||^2 $\) The first term in the objective function is also known as the data fitting term, while the second term, the penalty term, is completely independent of the data. For \(\alpha>0\), this objective function is always strongly convex, which leads to simple and robust optimization methods.
The benefit of Ridge regression is that it is much more stable than linear regression with OLS. If \(\alpha>0\), it always has a unique solution, no matter how badly behaved your data is. From a statistical perspective Ridge regression has the disadvantage that it is not an unbiased estimator: we explicitly biased our model to make the coefficients small, so predictions are biased towards zero. In predictive modeling, this is rarely an issue, however, you should keep it in mind.
The presence of a hyper-parameter could be seen either as an advantage or a disadvantage: one the one hand, it allows us to control the model fitting more closely, on the other it requires us to use some method to adjust the hyper-parameter, which makes the whole modeling process more complicated.
Mathematical details
(regularized) Empirical Risk Minimization¶
The objective function shown in TODO is a typical example of a mathematical framework that’s widely used in machine learning, known as regularized empirical risk minimization. As mentioned in TODO we didn’t mention it yet, the goal in supervised learning is usually to find a function \(f\) from a fixed familiy of fuctions \(F\) that minimizes
for some loss function \(\ell\). In other words, we want to minimize the expected loss between the prediction made by \(f\) and the true outcome \(y\), when sampling \(x\) and \(y\) from the data distribution. However, in practice, it’s usually impossible to access the data distribution \(p\), and instead, we have an i.i.d. sample from it, the training data.
The idea behind empirical risk minimization is that if we minimize the training set error, and the function \(f\) is simple, then the error on new samples will also be small. In other words, we replace the expectation in formula TODO by the empirical estimate on the training set: \($\min_{f\in F} \sum_{i=i}^n\ell(f(x_i), y_i)\)$ This is now a problem we can solve, and it is exactly the form of the objective found in OLS in equation TODO, where \(F\) is the family of all linear models, as parametrized by \(w\) and \(b\), and \(\ell\) is the squared loss. If we take this approach, it’s possible to proof theorems of the form TODO
In other words, we are trying to ensure a small error on the training set, and if we achive that, we can show that the test set error will also be small, if \(f\) is sufficiently simple. We could now try to optimize the bound in Equation TODO more directly, by optimizing both the training set error and encouraging the model to be simple. This leads to regularized empirical risk minimization in which we add an additional regularization term \(R\): \($ \min_{f \in F} \sum_{i=1}^n L(f(\mathbf{x}_i), y_i) + \alpha R(f) $\) This is the approach taken by ridge regression, where \(R\) is the squared norm of the coefficients. Maybe somewhat surprisingly, equation TODO summarizes most of supervised machine learning, and nearly every supervised algorithm in this book follows this idea. Linear models, support vector machines, neural networks and gradient boosting can all be formulated in this way, using different choices of the family of functions F, the loss \(\ell\) and the regularizer \(R\). It is also the basis of nearly all theoretical analysis of machine learning algorithms. Interestingly, it is now thought to not adequately explain the generalization ability of the very large neural networks used today, as they are not “simple” in any way we can quantify easily. This has led to a large body of interesting work investigating new theoretical underpinning for deep neural networks TODO reference. Please keep in mind that this is a very birds-eye view, as we are much more concerned with practical issues in this book. Theoretical machine learning is a fascinating topic, and you can learn much, much more in the amazing book TODO.
Coefficient of determination¶
To evaluate model fit for regression, scikit-learn by default uses the coefficient of determination, also known as \(R^2\), which is defined as follows: \($ R^2(y, \hat{y}) = 1 - \frac{\sum_{i=0}^{n - 1} (y_i - \hat{y}_i)^2}{\sum_{i=0}^{n - 1} (y_i - \bar{y})^2} $\) where \(\bar{y}\) is the mean response over the training set: \($ \bar{y} = \frac{1}{n} \sum_{i=0}^{n - 1} y_i\)$ The intuition of the measure it that it looks at the relative average distance between prediction and ground truth.
There are several definitions of this metric, but the one given in Equation TODO works for any model, and is what score will return for any regressor.
The benefit of this metric is that its scale is easily interpretable: a score of 1 means perfect prediction, while a score of 0 means constant or entirely random predictions.
Note that with this definition, the \(R^2\) score can be negative, which basically means that predictions are worse than just predicting the mean.
A disadvantage of this score is that it depends on the variance of the data it is applied to, which has several peculiar implications.
In particular, adding a data point with an extreme true response value will improve the overall score. Also, the mean is estimated independently when scoring the test set,
which can lead to artifacts if the test set is small. In particular, when computing the score on a single data point, it is undefined.
TODO reference Max Kuhn.
An alternative metric that has very different properties, is the root mean squared error (RMSE), which we’ll discuss in more detail in Chapter TODO.
Linear regression on the diabetes dataset¶
We start out with a relatively small dataset that comes with scikit-learn, the diabetes dataset. It has 442 rows corresponding to patients with diabetes, and 10 features describing different aspects of their health. The goal is to predict a quantiative measure of desease progression after one year.
# start by loading the dataset and doing a quick first look
from sklearn.datasets import load_diabetes
X, y = load_diabetes(as_frame=True, return_X_y=True)
print(X.shape)
X.head()
(442, 10)
| age | sex | bmi | bp | s1 | s2 | s3 | s4 | s5 | s6 | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.038076 | 0.050680 | 0.061696 | 0.021872 | -0.044223 | -0.034821 | -0.043401 | -0.002592 | 0.019908 | -0.017646 |
| 1 | -0.001882 | -0.044642 | -0.051474 | -0.026328 | -0.008449 | -0.019163 | 0.074412 | -0.039493 | -0.068330 | -0.092204 |
| 2 | 0.085299 | 0.050680 | 0.044451 | -0.005671 | -0.045599 | -0.034194 | -0.032356 | -0.002592 | 0.002864 | -0.025930 |
| 3 | -0.089063 | -0.044642 | -0.011595 | -0.036656 | 0.012191 | 0.024991 | -0.036038 | 0.034309 | 0.022692 | -0.009362 |
| 4 | 0.005383 | -0.044642 | -0.036385 | 0.021872 | 0.003935 | 0.015596 | 0.008142 | -0.002592 | -0.031991 | -0.046641 |
Before we’re staring to build our regression models, it’s a good idea to do some basic visualization to familiarize yourself with the dataset and spot any particularly salient aspects or data quality issues.
# It's a good idea to get an idea of the distribution of the target variable.
# Here we're using matplotlib's histogram function.
# Remember to set bins to auto, otherwise it's using 10 bins
# the histogram is somewhat skewed to the left, though not extremely
# and has a maximum around somewhere around 90
import matplotlib.pyplot as plt
y.hist(bins='auto')
<matplotlib.axes._subplots.AxesSubplot at 0x7fb5f6832b50>
At this point we split off a test set, which we will set aside for now. It can be used later to evaluate a final model of our choice.
# Split the data into training and test set before doing more in-depth visualization
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=42)
Given that the dataset has only ten features, it’s not too much to look at all of them. Here we’re doing a scatterplot of the feature on the x-axis against the target we want to predict on y-axis. This will show us any direct dependency of the target on each feature, but will not show more complex interactions.
# Create dataframe containing target for plotting
df_train = X_train.copy()
df_train['target'] = y_train
fig, axes = plt.subplots(2, 5, constrained_layout=True, figsize=(10, 4))
for col, ax in zip(X.columns, axes.ravel()):
df_train.plot(x=col, y='target', kind='scatter', ax=ax, legend=False, s=2, alpha=.6)
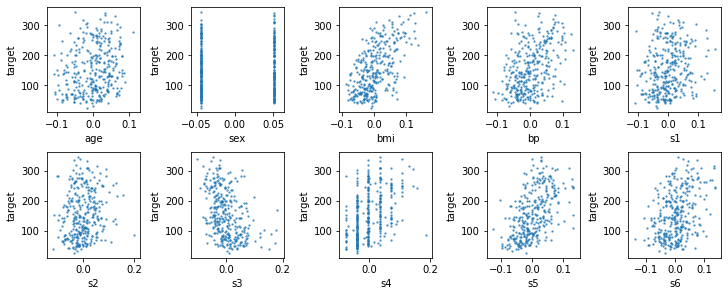
The first thing you might notice in these plots is that the data was already scaled, as the age is between -0.1 and 0.1. Therefore we will use the data as-is. You can also see that the sex column is a categorical feature, as might be expected. while all of the other features are continuous. Feature s4 is concentrated on some particular values, though. Looking at the relationship with the target, there is a clear dependency of the target on the BMI, and several of the other features also seem informative. It can also be a good idea to look at the correlation between features, which are best shown using a seaborn clustermap. The clustermap rearranges the features to make correlations more apparent.
import seaborn as sns
# plot correlation, annmotate with values
sns.clustermap(X_train.corr(), annot=True, cmap='bwr_r')
<seaborn.matrix.ClusterGrid at 0x7fb5f5bf1a60>
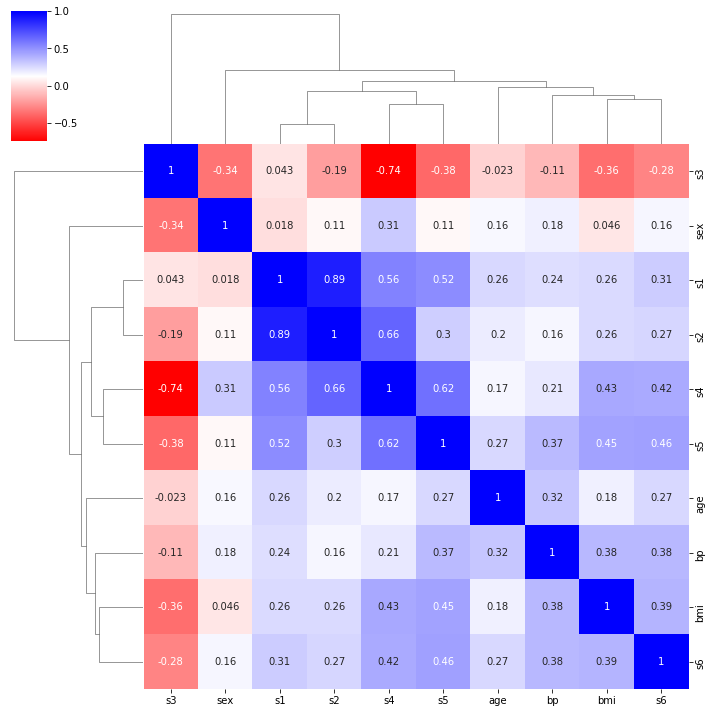
We can see that there’s a strong correlation between s1 and s2, and a relatively strong negative correlation between s3 and s4. We will keep all of the features for now.
Now we will use cross-validation to evaluate linear regression:
import pandas as pd
from sklearn.linear_model import Ridge, LinearRegression
from sklearn.model_selection import cross_validate
# run cross-validation, convert the results to a pandas dataframe for analysis
# return_train_score=True means that the training score is also computed
res = pd.DataFrame(cross_validate(LinearRegression(), X_train, y_train, return_train_score=True))
res
| fit_time | score_time | test_score | train_score | |
|---|---|---|---|---|
| 0 | 0.023110 | 0.001446 | 0.528990 | 0.506324 |
| 1 | 0.001793 | 0.001304 | 0.390191 | 0.539171 |
| 2 | 0.001826 | 0.001309 | 0.491299 | 0.521227 |
| 3 | 0.001717 | 0.001298 | 0.611033 | 0.480505 |
| 4 | 0.002076 | 0.001570 | 0.225245 | 0.561162 |
res.mean()
fit_time 0.006104
score_time 0.001385
test_score 0.449352
train_score 0.521678
dtype: float64
We can see that the model achives an \(R^2\) of around 0.52 on the training set, while the test set score has quite a bit of variablilty over the five cross-validation folds, with a mean score of 0.44. Given the small size of the dataset, such a variability is not very surprising, though.
Next, we can evaluate the Ridge model, with its default regularization parameter of alpha=1:
res = pd.DataFrame(cross_validate(Ridge(), X_train, y_train, return_train_score=True))
res
| fit_time | score_time | test_score | train_score | |
|---|---|---|---|---|
| 0 | 0.006885 | 0.001608 | 0.383890 | 0.397288 |
| 1 | 0.002185 | 0.001338 | 0.323097 | 0.428432 |
| 2 | 0.001623 | 0.001185 | 0.448959 | 0.402556 |
| 3 | 0.001570 | 0.001195 | 0.420870 | 0.373094 |
| 4 | 0.001701 | 0.001238 | 0.251547 | 0.437884 |
res.mean()
fit_time 0.002793
score_time 0.001313
test_score 0.365672
train_score 0.407851
dtype: float64
Both training and test score are lower using Ridge, though there is less variability in the test set score. The lower scores indicate that the model was overly restricted by the penalty term. There is no reason the default parameters would be optimal, an so we should always tune the regularization parameter in Ridge using GridSearchCV. Regularization parameters such as alpha in Ridge are usually searched on a logarithmic scale. Given that using alpha=1 seems already too much weight on the regularization, we pick a grid of [0.0001, 0.001, 0.01, 0.1, 1, 10]:
import numpy as np
from sklearn.model_selection import GridSearchCV
# logspace creates numbers that are evenly spaces in log-space
# it uses a base of 10 by default, here starting from 10^-4 to 10^1, with 6 steps in total
param_grid = {'alpha': np.logspace(-4, 1, 6)}
param_grid
{'alpha': array([1.e-04, 1.e-03, 1.e-02, 1.e-01, 1.e+00, 1.e+01])}
# define and execute grid-search
# return training scores
grid = GridSearchCV(Ridge(), param_grid, return_train_score=True)
grid.fit(X_train, y_train)
print(grid.best_score_)
print(grid.best_params_)
0.4516801116608531
{'alpha': 0.1}
The best cross-validation score of 0.45 is achieved with alpha=0.1. However, it’s not substantially better than the score achieved by linear regression.
We should confirm that the parameter range we chose is appropriate by looking at the training and validation scores for the different parameters, stored in grid.cv_results_:
res = pd.DataFrame(grid.cv_results_)
res
| mean_fit_time | std_fit_time | mean_score_time | std_score_time | param_alpha | params | split0_test_score | split1_test_score | split2_test_score | split3_test_score | ... | mean_test_score | std_test_score | rank_test_score | split0_train_score | split1_train_score | split2_train_score | split3_train_score | split4_train_score | mean_train_score | std_train_score | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.001814 | 0.000098 | 0.001335 | 0.000231 | 0.0001 | {'alpha': 0.0001} | 0.528816 | 0.390597 | 0.491218 | 0.610916 | ... | 0.449455 | 0.132386 | 4 | 0.506324 | 0.539168 | 0.521226 | 0.480504 | 0.561159 | 0.521676 | 0.027553 |
| 1 | 0.001347 | 0.000043 | 0.001025 | 0.000084 | 0.001 | {'alpha': 0.001} | 0.527445 | 0.393458 | 0.490536 | 0.609957 | ... | 0.450115 | 0.130527 | 3 | 0.506268 | 0.538987 | 0.521141 | 0.480426 | 0.560971 | 0.521559 | 0.027506 |
| 2 | 0.001606 | 0.000331 | 0.001191 | 0.000246 | 0.01 | {'alpha': 0.01} | 0.521839 | 0.400945 | 0.487998 | 0.604883 | ... | 0.451007 | 0.124386 | 2 | 0.505220 | 0.535916 | 0.519616 | 0.478931 | 0.557753 | 0.519487 | 0.026768 |
| 3 | 0.001398 | 0.000105 | 0.001022 | 0.000088 | 0.1 | {'alpha': 0.1} | 0.513270 | 0.401617 | 0.498042 | 0.584170 | ... | 0.451680 | 0.111577 | 1 | 0.498822 | 0.527579 | 0.512636 | 0.471906 | 0.548880 | 0.511965 | 0.026017 |
| 4 | 0.001381 | 0.000096 | 0.001033 | 0.000081 | 1 | {'alpha': 1.0} | 0.383890 | 0.323097 | 0.448959 | 0.420870 | ... | 0.365672 | 0.070926 | 5 | 0.397288 | 0.428432 | 0.402556 | 0.373094 | 0.437884 | 0.407851 | 0.023123 |
| 5 | 0.001469 | 0.000108 | 0.001089 | 0.000095 | 10 | {'alpha': 10.0} | 0.079865 | 0.107844 | 0.149916 | 0.118348 | ... | 0.094234 | 0.045432 | 6 | 0.126741 | 0.138133 | 0.120183 | 0.118031 | 0.137972 | 0.128212 | 0.008532 |
6 rows × 21 columns
# plot training score vs parameter alpha, with x on logscale
# use std over cross-validation folds for error bars
ax = res.plot(x='param_alpha', y='mean_train_score', yerr='std_train_score', logx=True)
# same for test set, plot in the same axes
res.plot(x='param_alpha', y='mean_test_score', yerr='std_test_score', ax=ax)
<matplotlib.axes._subplots.AxesSubplot at 0x7fb5f50c9310>
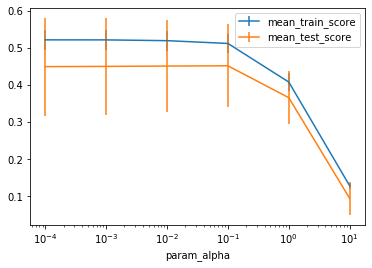
From the plot we can see that as we expected, traihning and test set score are low for alpha=1 and even lower for higher alpha. There seems little difference between the three lowest values of alpha; using alpha=10**-4 is low enough to be roughly equivalent to linear regression. We can see that using alpha=10*-1=0.1 performs slightly worse on the training set, but has slightly lower standard deviation on the test set. However, this is not much of an advantage over just using LinearRegression.
This is not entirely surprising as the data has many more samples than features, and there are only moderate correlations in the dataset. We can likely eliminate any advantage Ridge might have by dropping the highly correlated features s2 and s4:
# create a new data matrix without s2 and s4
X_train_sub = X_train.drop(columns=['s2', 's4'])
X_train_sub.head()
| age | sex | bmi | bp | s1 | s3 | s5 | s6 | |
|---|---|---|---|---|---|---|---|---|
| 16 | -0.005515 | -0.044642 | 0.042296 | 0.049415 | 0.024574 | 0.074412 | 0.052280 | 0.027917 |
| 408 | 0.063504 | -0.044642 | -0.050396 | 0.107944 | 0.031454 | -0.017629 | 0.058039 | 0.040343 |
| 432 | 0.009016 | -0.044642 | 0.055229 | -0.005671 | 0.057597 | -0.002903 | 0.055684 | 0.106617 |
| 316 | 0.016281 | 0.050680 | 0.014272 | 0.001215 | 0.001183 | -0.032356 | 0.074968 | 0.040343 |
| 3 | -0.089063 | -0.044642 | -0.011595 | -0.036656 | 0.012191 | -0.036038 | 0.022692 | -0.009362 |
# run cross-validation on the reduced dataset
res = pd.DataFrame(cross_validate(LinearRegression(), X_train_sub, y_train, return_train_score=True))
res
| fit_time | score_time | test_score | train_score | |
|---|---|---|---|---|
| 0 | 0.001703 | 0.001000 | 0.514748 | 0.504328 |
| 1 | 0.001383 | 0.000959 | 0.424273 | 0.528065 |
| 2 | 0.001338 | 0.001132 | 0.482717 | 0.516778 |
| 3 | 0.001575 | 0.001089 | 0.600992 | 0.477712 |
| 4 | 0.001331 | 0.000943 | 0.234819 | 0.553382 |
res.mean()
fit_time 0.001466
score_time 0.001025
test_score 0.451510
train_score 0.516053
dtype: float64
The results on the reduced dataset are basically identical to the results from ridge, and have lower variance than the results of Linear Regression on the original dataset. TODO inspect coefficients.
Linear regression on the Triazine Dataset¶
Next we will look at a dataset with quite different characteristics, the triazine dataset, which was collected in a drug discovery application.
from sklearn.datasets import fetch_openml
X, y = fetch_openml('triazines', return_X_y=True, as_frame=True)
X.head()
/home/andy/checkout/scikit-learn/sklearn/datasets/_openml.py:373: UserWarning: Multiple active versions of the dataset matching the name triazines exist. Versions may be fundamentally different, returning version 1.
warn("Multiple active versions of the dataset matching the name"
| p1_polar | p1_size | p1_flex | p1_h_doner | p1_h_acceptor | p1_pi_doner | p1_pi_acceptor | p1_polarisable | p1_sigma | p1_branch | ... | p6_polar | p6_size | p6_flex | p6_h_doner | p6_h_acceptor | p6_pi_doner | p6_pi_acceptor | p6_polarisable | p6_sigma | p6_branch | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.58 | 0.233 | 0.100 | 0.1 | 0.100 | 0.5 | 0.1 | 0.5 | 0.900 | 0.1 | ... | 0.9 | 0.5 | 0.1 | 0.1 | 0.1 | 0.1 | 0.9 | 0.9 | 0.633 | 0.633 |
| 1 | 0.10 | 0.100 | 0.100 | 0.1 | 0.100 | 0.1 | 0.1 | 0.1 | 0.100 | 0.1 | ... | 0.1 | 0.1 | 0.1 | 0.1 | 0.1 | 0.1 | 0.1 | 0.1 | 0.100 | 0.100 |
| 2 | 0.26 | 0.100 | 0.100 | 0.1 | 0.100 | 0.1 | 0.1 | 0.1 | 0.100 | 0.1 | ... | 0.3 | 0.1 | 0.1 | 0.1 | 0.1 | 0.1 | 0.1 | 0.1 | 0.100 | 0.100 |
| 3 | 0.42 | 0.500 | 0.633 | 0.1 | 0.633 | 0.5 | 0.1 | 0.5 | 0.367 | 0.1 | ... | 0.1 | 0.1 | 0.1 | 0.1 | 0.1 | 0.1 | 0.1 | 0.1 | 0.100 | 0.100 |
| 4 | 0.58 | 0.233 | 0.100 | 0.1 | 0.100 | 0.5 | 0.1 | 0.5 | 0.900 | 0.1 | ... | 0.1 | 0.1 | 0.1 | 0.1 | 0.1 | 0.1 | 0.1 | 0.1 | 0.100 | 0.100 |
5 rows × 60 columns
X.shape
(186, 60)
This dataset has 186 rows and 60 features, which is likely to pose a problem to unpenalized linear regression.
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=42)
We can try to plot all features, however, looking at 60 plots becomes quickly overwhelming.
# Create dataframe containing target for plotting
df_train = X_train.copy()
df_train['target'] = y_train
fig, axes = plt.subplots(8, 8, figsize=(10, 10), constrained_layout=True)
for col, ax in zip(X.columns, axes.ravel()):
df_train.plot(x=col, y='target', kind='scatter', ax=ax, legend=False, s=2, alpha=.6)
ax.set_ylabel('')

However, we can see that p5_flex and p5_h_doner are constant, and therefore can be dropped:
X_train[['p5_flex', 'p5_h_doner']].std()
p5_flex 0.0
p5_h_doner 0.0
dtype: float64
X_train = X_train.drop(columns=['p5_flex', 'p5_h_doner'])
X_train.corr().shape
(58, 58)
#TODO why is this not showiung the full matrix?
sns.clustermap(X_train.corr(), cmap='bwr_r')
<seaborn.matrix.ClusterGrid at 0x7fb5f5e5e730>
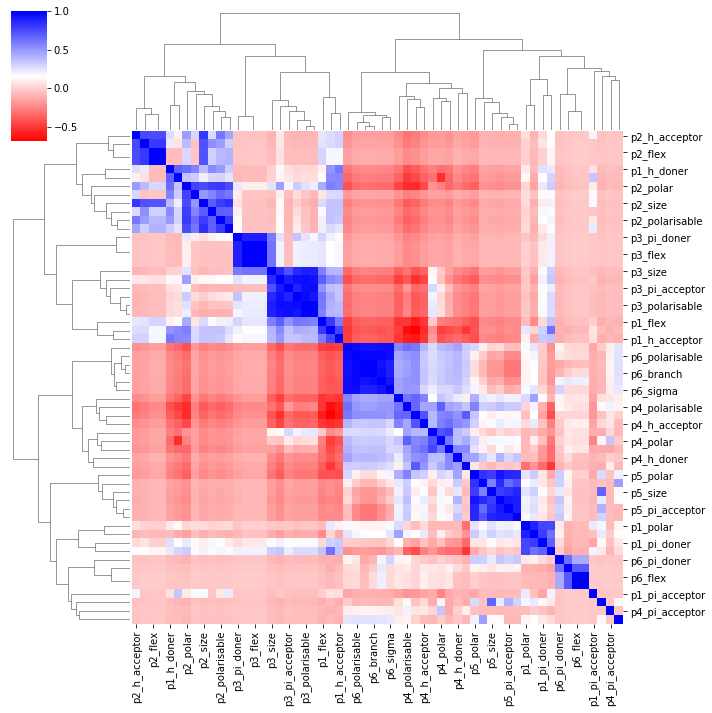
The correlations in this datset are much more complex as you can see. Still, we can use LinearRegression as a baseline:
res = pd.DataFrame(cross_validate(LinearRegression(), X_train, y_train, return_train_score=True))
res.mean()
fit_time 3.137350e-03
score_time 1.449299e-03
test_score -1.222657e+20
train_score 4.868313e-01
dtype: float64
While the training score is 0.48, the test score is very, very negative, indicating numeric instabilities in the model. Given the strong correlations in the dataset, that’s not surprising. Ridge will fare much better here. As we expect to require a lot of regularization, we’ll change the grid a bit to go until alpha=1000:
param_grid = {'alpha': np.logspace(-2, 3, 6)}
param_grid
{'alpha': array([1.e-02, 1.e-01, 1.e+00, 1.e+01, 1.e+02, 1.e+03])}
grid = GridSearchCV(Ridge(), param_grid, return_train_score=True)
grid.fit(X_train, y_train)
print(grid.best_score_)
print(grid.best_params_)
0.07556489256250143
{'alpha': 10.0}
The best average score is 0.07, which is quite low, indicating that the model is only slightly better than predicting the mean. Again, we can look at the results for all parameters to get a better idea of the role of alpha:
res = pd.DataFrame(grid.cv_results_)
ax = res.plot(x='param_alpha', y='mean_train_score', yerr='std_train_score', logx=True)
res.plot(x='param_alpha', y='mean_test_score', yerr='std_test_score', ax=ax)
# cut off scores much below 0
ax.set_ylim(-.1, .5)
(-0.1, 0.5)
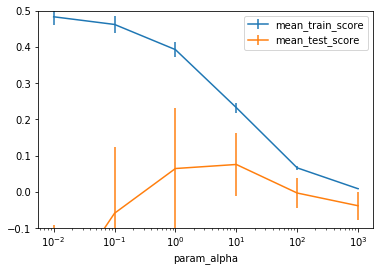
You can see a clear optimum around alpha=10, and a very characteristic pattern that mirrors the plot in TODO overfitting underfitting very closely. The more we increase alpha, the lower the training set score goes - which is expected, as a larger value of alpha puts less emphasis on the training set error. On the test set, we can see that for low values of alpha, the results are terrible, while for very high values of alpha, they go towards 0. Between these extremes, there is a clear sweetspot where the penalty reduces model complexity, but still allows fitting a model that can make reasonable predictions (though an R^2 of 0.07 potentially stretches the meaning of “reasonable” a bit).
Given the numeric instabilities, we won’t bother visualizing the coefficients for linear regression, but we will show them for the ridge model for several values of alpha.
# extract the model with the best parameters from our grid-search (alpha=10)
ridge = grid.best_estimator_
ridge
Ridge(alpha=10.0)
# instantiate and fit models for two neighboring values of alpha
ridge100 = Ridge(alpha=100).fit(X_train, y_train)
ridge1 = Ridge(alpha=1).fit(X_train, y_train)
plt.figure(figsize=(8, 4))
# plot coefficients for all three models
plt.plot(ridge1.coef_, 'o', label="alpha=1")
plt.plot(ridge.coef_, 'o', label=f"alpha={ridge.alpha:.0f}")
plt.plot(ridge100.coef_, 'o', label="alpha=100")
plt.ylabel("coefficient")
plt.xlabel("feature index")
plt.xticks(np.arange(X_train.shape[1]), X_train.columns, rotation=90)
plt.legend()
<matplotlib.legend.Legend at 0x7fb5d04f15e0>
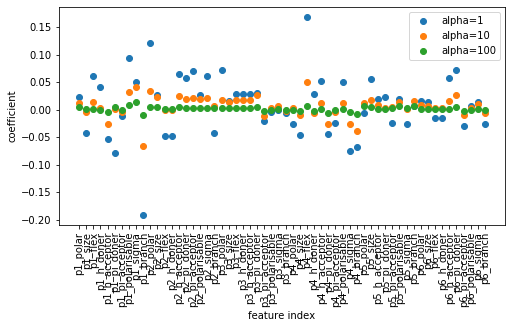
You can see that as we discussed above, increasing alpha will shrink each coefficient more towards zero. Usually the sign of the coefficient stays the same, independent of alpha, however, that’s not guaranteed to happen.
TODO learning curve maybe?
Lasso Regression¶
Another very commonly used model for regression is Lasso (TODO short for). Similar to ridge, lasso also penalizes large values of the coefficients. However, instead of using the euclidean norm or L2 norm as in Ridge, lasso uses the sum of absolute values, also known as the L1 norm. This is only a small change in the objective, however, it has a big effect on the model and optimization. While in Ridge, all of the coefficients are pushed towards zero, they are unlikely to ever be exactly zero. Using lasso on the other hand, increasing the regularization parameter alpha will make more and more parameters exactly zero. This is a form of automatic feature selection, and can be helpful to find more compact and interpretable models.
Mathematical details
The motivation for lasso is relatively straight-forward: find a linear model with as few nonzero coefficients as possible. While this is a very natural requirement, solving this problem exactly is usually not feasible (it would be using what’s known as the L-infinity norm as penalty, which yields an NP-Hard optimization problem TODO Rudin can solve it). Lasso can be seen as a relaxed version of this problem that is much more easily solvable but still results in a reduced set of features. Lasso can be written as: \($ \min_{w \in \mathbb{R}^p, b\in\mathbb{R}} \sum_{i=1}^n (w^T\mathbf{x}_i + b - y_i)^2 + \alpha ||w||_1 $\) As Ridge, this is a (TODO strongly?) convex optimization problem for alpha>0. However, unlike lasso, it’s not a least squares problem, and is not differentiable. This makes the optimization slightly more tricky; however, it’s a well-studied problem with plenty of algorithms available to solve it. Read more in ESL TODO.
from sklearn.linear_model import Lasso
# TODO explain options
param_grid = {'alpha': np.logspace(-5, 0, 10)}
grid = GridSearchCV(Lasso(max_iter=10000, normalize=True), param_grid, cv=10)
grid.fit(X_train, y_train)
print(grid.best_score_)
print(grid.best_params_)
0.021748024821626865
{'alpha': 0.0004641588833612782}
For this dataset, Lasso doesn’t fare as well as Ridge did. However, the model is much simpler, it only uses 15 out of the 62 features:
np.sum(grid.best_estimator_.coef_ != 0)
15
We can look at the training and validation scores, as well as how the alpha parameter influences the number of features TODO recreate plot:
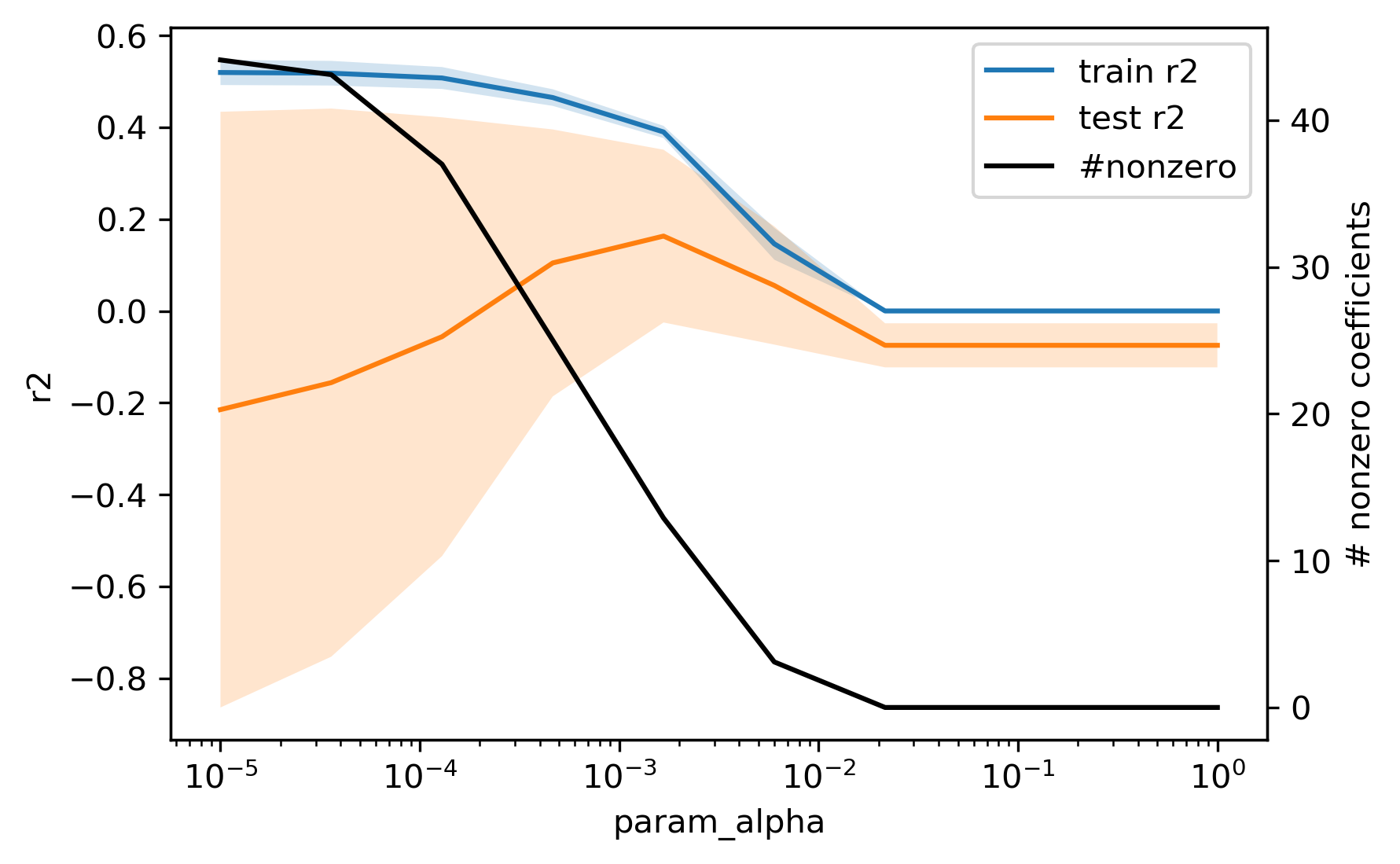
As you can see, increasing alpha decreases the amount of non-zero features and around alpha=0.05, all features become zero. Often, Ridge performs better in terms of cross-validation score, but lasso will usually provide a more simple model. There is one caveat for the interpretability of lasso, though. In a case such as the triazine dataset we’re using here, with many highly correlated features, the selection of features made by Lasso is very unstable. Lasso will usually select one out of a group of correlated features, and which one is selected can easily change, for example when splitting the data differently:
# split data same as above
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=42)
# use alpha close to optimum from above
lasso = Lasso(max_iter=10000, normalize=True, alpha=0.0005)
lasso.fit(X_train, y_train)
# we validate the model on the test set to see that it's reasonable.
# While it's quite a bit better than the mean cross-validated score,
# it's within the range of the individual values
lasso.score(X_test, y_test)
0.23610676824170862
Now let’s look at the columns that were selected by Lasso (by virtue of having non-zero components). We’re using a threshold slightly larger than zero to account for floating point imprecisions.
X_train.columns[np.abs(lasso.coef_) > 1e-10]
Index(['p1_polarisable', 'p1_branch', 'p2_polar', 'p2_h_acceptor', 'p3_flex',
'p3_pi_doner', 'p4_flex', 'p4_sigma', 'p4_branch', 'p5_size',
'p6_h_acceptor', 'p6_pi_doner'],
dtype='object')
And let’s look at the total count of selected features:
np.sum(np.abs(lasso.coef_) > 1e-10)
12
Now let’s change the initial splitting of the data and repreat the same analysis:
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=23)
lasso2 = Lasso(max_iter=10000, normalize=True, alpha=0.0005)
lasso2.fit(X_train, y_train)
lasso2.score(X_test, y_test)
0.152780778897191
X_train.columns[np.abs(lasso2.coef_) > 1e-10]
Index(['p1_h_doner', 'p1_h_acceptor', 'p1_polarisable', 'p1_sigma',
'p1_branch', 'p2_polar', 'p2_pi_doner', 'p3_flex', 'p3_pi_doner',
'p4_flex', 'p4_pi_doner', 'p4_pi_acceptor', 'p4_sigma', 'p4_branch',
'p5_size', 'p5_polarisable', 'p6_h_acceptor', 'p6_pi_doner'],
dtype='object')
np.sum(np.abs(lasso2.coef_) > 1e-10)
18
You can see that instead of 12 features in the first split, the second split selected 18 features using the same hyper-parameters. Most of the colums with non-zero coefficient in the first split also have non-zero coefficients in the second split, but not all of them: p2_h_acceptor was not selected for example. Therefore any interpretation about which coefficents where selected is not very reliable if correlated features are present.
Elastic Net¶
Finally, there is a model that combines the two penalization methods of Ridge and Lasso, applying both L1 and L2 regularization. This model is known as Elastic Net, and has two hyper-parameters to control the two different kinds of regularization. This leads to a model that is more general than either, can lead to sparse solutions, but also can be more accurate and stable than Lasso.
Mathematical details
The objective function for Elastic Net is quite straight-forward: it contains the least square data fitting term that we saw in all the models in this section, plus the L1 norm (sum of absolute values) plus the L2 norm (euclidean length) of the coefficient vector. The most obvious way to adjust the regularization strength is by multiplying each with its own hyper-parameter, called \(\alpha_1\) and \(\alpha_2\) respectively:
\($\min_{w \in \mathbb{R}^p, b\in\mathbb{R}} \sum_{i=1}^n ||w^T\mathbf{x}_i + b - y_i||^2 + \alpha_1 ||w||_1 + \alpha_2 ||w||^2_2 $\)
The parametrization in scikit-learn is slightly different, but equivalent:
\($\min_{w \in \mathbb{R}^p, b\in\mathbb{R}} \sum_{i=1}^n (w^T\mathbf{x}_i + b - y_i)^2 + \alpha \eta ||w||_1 + \alpha (1 - \eta) ||w||^2_2 $\)
Here, \(\alpha\) is the overall regularization strength, while \(\eta\) (called l1_ratio in the code) is the relative strength of the L1 compared to the L2 penalty.
The two hyper-parameters of the model in scikit-learn are alpha and l1_ratio, where alpha is the overall strength of regularization and should be searched on a logarithmic scale, similar to Ridge and Lasso. The l1_ratio hyper-parameter determines the relative strength of the two regularization options, with an l1_ratio of 1 resulting in a model that’s equivalent to Lasso, and an l1_ratio of 0 resulting in a model that’s equivalent to Ridge. I’m unaware of general guidelines for tuning the l1_ratio parameter, but often values close to 0 (like 0.01) or close to 1 (like 0.99) seem to be working well.
Let’s see how well this model does on the Triazine dataset:
from sklearn.linear_model import ElasticNet
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=42)
param_grid = {'alpha': np.logspace(-4, -1, 10),
'l1_ratio': [0.01, .1, .5, .6, .7, .8, .9, .95, 1]}
grid = GridSearchCV(ElasticNet(max_iter=10000, normalize=True), param_grid, cv=10)
grid.fit(X_train, y_train)
print(grid.best_params_)
print(grid.best_score_)
{'alpha': 0.001, 'l1_ratio': 0.8}
0.05746406025336763
We can also compute the number of non-zero coefficients of the best model found:
np.sum(np.abs(grid.best_estimator_.coef_) > 1e-10)
10
With just 10 non-zero parameters, this model seem to be performing better than previous models (though still quite bad on average).
As our grid-search now contains two hyper-parameters, the results are less easy to visualize. A common way to visualize two-dimensional hyper-parameter spaces is using a heat-map. We can do this either using matplotlib, pandas or seaborn.
The results are stored in the cv_results_ attribute as before, but now this dictionary contains two hyper-parameters:
cv_res = pd.DataFrame(grid.cv_results_)
cv_res.head()
| mean_fit_time | std_fit_time | mean_score_time | std_score_time | param_alpha | param_l1_ratio | params | split0_test_score | split1_test_score | split2_test_score | split3_test_score | split4_test_score | split5_test_score | split6_test_score | split7_test_score | split8_test_score | split9_test_score | mean_test_score | std_test_score | rank_test_score | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.004945 | 0.000487 | 0.001218 | 0.000197 | 0.0001 | 0.01 | {'alpha': 0.0001, 'l1_ratio': 0.01} | 0.102067 | -0.667312 | -0.209677 | 0.435300 | -0.015640 | -0.291946 | -1.325380 | -0.396977 | 0.062931 | -0.322138 | -0.262877 | 0.458864 | 90 |
| 1 | 0.003518 | 0.000752 | 0.001130 | 0.000049 | 0.0001 | 0.1 | {'alpha': 0.0001, 'l1_ratio': 0.1} | 0.102685 | -0.701441 | -0.198354 | 0.431830 | -0.003047 | -0.262406 | -1.296583 | -0.393008 | 0.067626 | -0.310960 | -0.256366 | 0.455727 | 89 |
| 2 | 0.002625 | 0.000199 | 0.001152 | 0.000132 | 0.0001 | 0.5 | {'alpha': 0.0001, 'l1_ratio': 0.5} | 0.092725 | -0.711939 | -0.137158 | 0.411446 | -0.023455 | -0.122103 | -1.159561 | -0.388860 | 0.095857 | -0.258183 | -0.220123 | 0.424984 | 88 |
| 3 | 0.002631 | 0.000131 | 0.001098 | 0.000015 | 0.0001 | 0.6 | {'alpha': 0.0001, 'l1_ratio': 0.6} | 0.087842 | -0.699913 | -0.120273 | 0.405647 | -0.017997 | -0.105653 | -1.127130 | -0.384588 | 0.104705 | -0.246586 | -0.210395 | 0.416597 | 86 |
| 4 | 0.002780 | 0.000186 | 0.001087 | 0.000004 | 0.0001 | 0.7 | {'alpha': 0.0001, 'l1_ratio': 0.7} | 0.084404 | -0.686281 | -0.106664 | 0.400745 | -0.011885 | -0.092287 | -1.098836 | -0.371369 | 0.113662 | -0.238139 | -0.200665 | 0.408786 | 85 |
I find it easiest to create a pivot table between the two parameters, containing the mean test score as the values:
res = pd.pivot_table(cv_res,
values='mean_test_score', index='param_alpha', columns='param_l1_ratio')
res
| param_l1_ratio | 0.01 | 0.10 | 0.50 | 0.60 | 0.70 | 0.80 | 0.90 | 0.95 | 1.00 |
|---|---|---|---|---|---|---|---|---|---|
| param_alpha | |||||||||
| 0.000100 | -0.262877 | -0.256366 | -0.220123 | -0.210395 | -0.200665 | -0.189989 | -0.182104 | -0.178336 | -0.175988 |
| 0.000215 | -0.211292 | -0.199394 | -0.149264 | -0.135405 | -0.120616 | -0.103799 | -0.086235 | -0.078930 | -0.073370 |
| 0.000464 | -0.163388 | -0.148679 | -0.060443 | -0.038661 | -0.019982 | -0.004912 | 0.008836 | 0.015728 | 0.021748 |
| 0.001000 | -0.118270 | -0.089094 | 0.028846 | 0.046660 | 0.054013 | 0.057464 | 0.056977 | 0.054727 | 0.052289 |
| 0.002154 | -0.077946 | -0.035164 | 0.024236 | 0.010323 | -0.007533 | -0.030427 | -0.057871 | -0.071630 | -0.085981 |
| 0.004642 | -0.050726 | -0.002223 | -0.121608 | -0.160650 | -0.185764 | -0.184572 | -0.181428 | -0.181428 | -0.181428 |
| 0.010000 | -0.042396 | -0.039982 | -0.181428 | -0.181428 | -0.181428 | -0.181428 | -0.181428 | -0.181428 | -0.181428 |
| 0.021544 | -0.056039 | -0.143407 | -0.181428 | -0.181428 | -0.181428 | -0.181428 | -0.181428 | -0.181428 | -0.181428 |
| 0.046416 | -0.090926 | -0.181428 | -0.181428 | -0.181428 | -0.181428 | -0.181428 | -0.181428 | -0.181428 | -0.181428 |
| 0.100000 | -0.138160 | -0.181428 | -0.181428 | -0.181428 | -0.181428 | -0.181428 | -0.181428 | -0.181428 | -0.181428 |
You can now plot this dataframe easily using seaborn’s heatmap function:
sns.heatmap(res, annot=True)
<matplotlib.axes._subplots.AxesSubplot at 0x7fb5c57b7970>

Given the small size of the dataset and the instability in lasso we observed above, the conclusions from this plot should be taken with caution, but it seems that alpha=0.001, with an l1_ratio between 0.7 and 0.95 seems to be working best. We could refine our search and/or use a more elaborate cross-validation strategy if we wanted to tune parameters further. Keep in mind how many different models we trained here: each entry in the heatmap corresponds to running cross-validation with this combination of parameters, so the total number of models we trained is 9 * 10 * 10 = 900.
Finally, let’s evaluate our model on the test set:
grid.score(X_test, y_test)
0.23255259638322634
The model is about as good as the first Lasso model aboe, though it uses two features less.
This concludes our discussion of linear models for regression. There are several other kinds that we did not discuss, in particular those that model specific output distributions (such as count data or logistic data), called generalized linear models, and models that are robust to outliers in the training data, such as Huber’s regressor and RANSAC. However, in most cases, using one of the above models is quite sufficient, and problem formulation and feature engineering will likely play a larger role in determining your success than slight modifications in the model.
Using Ridge is a safe default choice for most applications, though you should always ensure propers scaling of the data and tuning of the hyper-parameter alpha. Lasso and ElasticNet can be useful for finding sparse solution and doing automatic feature selection, though their results can be highly unstable if features are correlated. If a stable, interpretable selection of coefficient is sought, removing correlated features is a potential solution.